- Select a language for the TTS:
- UK English Female
- UK English Male
- US English Female
- US English Male
- Australian Female
- Australian Male
- Language selected: (auto detect) - EN
Play all audios:
Content Section * Introduction 2. Related work on Hyperparameter Tuning 3. Related work on Architecture Search 4. LEAF AutoML Overview 5. Comparing LEAF vs MOE (autoML from Yelp) vs Google
AutoML vs others INTRODUCTION AutoML’s task is expected to do the following: algorithm Selection, hyper parameter tuning of models, iterative modeling, and model assessment. In the other
word, AutoML’s tasks are hyper-parameter tuning and algorithm selections. I recommend those who are not familiar with AutoML to check out the following link
https://determined.ai/blog/neural-architecture-search/. Author clearly explains definition of automl, neural architecture search, and hyper-parameters optimization. CASH is a challenge whose
goal is to find an algorithm or neural network models that could identify the best set of hyper parameters of a selected algorithms for a given tasks. But why do we need AutoML? There are 2
main objectives that AutoML could provide * to find innovative configurations of DNNs that also perform well without the need of domain experts (HYPER-PARAMETER AND ARCHITECTURE SEARCH) *
to find configurations that are small enough to be practical such as DNNs on mobile phone (NETWORK COMPLEXITY) BACKGROUND There are many techniques that are often used in AutoML research.
Popular techniques are Reinforcement learning, Evolutionary Algorithm, and Bayesian Optimization. Most of the researches does “partial optimization.” Partial optimization only attempts to
optimize 1 of the 2 aspect of CASH challenges either hyper-paramter tuning (HPT) or neural architecture search (NAS). BACKGROUND: HYPER-PARAMETERS TUNING Popular but less sophisticated
techniques used for HPT are Grid search and Random search. Grid search is used when no hyper-parameters are KNOWN TO BE MORE IMPORTANT THAN OTHERS_._ Otherwise, random search are preferred.
Furthermore, cost of running grid search increases exponentially as number of Hyper-parameters increases More sophisticated techniques of HP is Gaussian processes (GP). (video reference for
more detail: GAUSSIAN PROCESSES) It first creates a probability distribution of functions (also known as Gaussian process) that best fits the objective function and then USES THAT
DISTRIBUTION TO DETERMINE WHERE TO SAMPLE NEXT_._ Disadvantage of GP is that it is computationally intensive and scale cubically with the number of sample points. (more points, more
information, better prediction) In addition, it is important to add that when number of HP is more than 10 ~15 parameters, its ability to find the most optimal hyper-parameters dropped
noticably. AutoML is expected to be a very profitable business. For this reason, many companies are building their own AutoML including Giant Company such as Google AutoML, Metric
Optimization Engine (MOE) from Yelp, TLC from Microsoft. Each company has its own strategy. For example, Google AutoML is a black box while MOE is transparent but it only does
hyper-paramteter tuning. The presented paper introduced new algorithm called LEAF. (Learning Evolutionary AI Framework) Advantage of LEAF is that it does both HT and NAS. At its core, LEAF
uses another evolutionary algorithm, called CoDeepNEAT. Evolutaionary Algorithm improves iteratively upon selected the best “population” each time the solution “evolves.” (select samples,
evolves, repeat) BACKGROUND: NEURAL ARCHITECTURE SEARCH Reinforcement Leanring is often used in NAS, but its down fall is that its optimization process can either be a linear or a tree like
structure, so search space must be selected by the user beforehand. It is also VERY computationally intensive. (failed to satisfy 2nd objective mentioned above) EA models are often modified
version of NEAT model. Other technique includes Genetic Programming, Hierarchical Evolution. EA is a black box which is an advantage in that it has larger search space. LEAF OVERVIEW Search
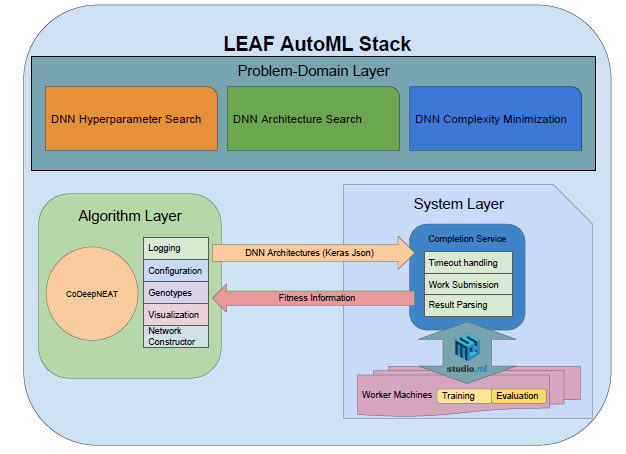
Space must be defined before computing LEAF eg. LSTM or CNNs. There are 3 components of LEAF: * Algorithm layer * System layer * Problem-domain layer. Figure 1: A visualization of LEAF and
its internal subsystems. The three main components are: (1) the algorithm layer which uses CoDeepNEAT to evolve hyperparameters or neural networks, (2) the system layer which helps train and
evaluate the networks evolved by the algorithm layer, and (3) the problem-domain layer, which utilizes the two previous layers to optimize DNNs. ALGORITHM LAYER Terminology section >
Population divides into many species. > > One species has many chromosomes individuals > > Species = Modules > > Chromosome, Individual= Graph > > Node = Layer
> > Assembled Networks composes of many chromosomes within the same > species LEAF algorithm Step by Step Explaination * group species; specifies evolves independently
proportionally to its fitness. * chromosome (graph) evolves by replacing its nodes to member of its species (replace nodes by other chromosome within the same species) * node mutates HP ,
for each node within a chromosome. (through Gaussian distribution, and random bit flip) * fitness evaluation of the assembled networks as a whole is attributed back to BLUEPRINT, and MODULES
as the average fitness of all the assembled networks contains the blueprint or modules (1 BLUEPRINT IS A PART OF MANY ASSEMBLES -> BLUEPRINT FITNESS = AVERAGE ALL THE ASSEMBLE) * repeat
until satisfy A node (local HP) determines type of layer, and properties of layers. (kernel size, number of neural, activation function) A chromosome (global HP) contains a set of global HP
such as learning rate, training algorithm, and data preprocessing) CoDeepNEAT is similar to a conventional genetic algorithm in that there is elitist selection and the hyperparameters_
_UNDERGO UNIFORM MUTATION AND CROSSOVER_._ it still has NEAT’s speciation mechanism, which PROTECTS NEW AND INNOVATIVE HYPERPARAMETERS. On the other hand, CoDeepNEAT is different from NEAT
in that nodes is NOT A NEURON BUT A LAYER. Its main purpose is to narrow down search space. A node contains real and binary values parameters. Mutation is down in 2 ways: * mutate thought
uniform Gaussian distribution * random bit flipping. Unlike NEAT, edges has no weight, it only indicate connection between nodes. (it removes bias towards combination of few nodes, instead
focus on the graph as a whole) SYSTEM LAYERS LEAF is run in parallel search method. GPUs are on the clouds service. This paper runs on Microsoft Azure. LEAF uses complete service API called
‘StudioML’. Step by Step Explaination * Algorithm layer sends networks ready for fitness evaluation in the Keras-JSON to the system layer server node. * system layer submits the network to
the complete service * results are returns one at a time with no order garantee. PROBLEM DOMAIN LAYERS LEAF can do NAS in both one task and multi task. The foundation is the SOFT-ORDERING
MULTITASK ARCHITECTURE where each level of a fixed linear DNN consists of a fixed number of modules. (1 TASK LEVEL HAS MANY SPECIES) These modules are then used to a different degree for the
different tasks. (CUSTOMIZE OPTIMIZATION TECHNIQUE TO A TAKS) LEAF extends this multi task learning (MTL) architecture by coevolving both the module architectures and the blueprint (routing
between the modules) of the DNN. LEAF also support multi-objective search. In a single objective search, elists modules and blueprint are ranked and top rank will be selected. Ranking is
done purely using fitness function. In the multi-object search, ranking is computed from Pareto fonts generated from number of objectives. (the paper used 2 objectives: primary and secondary
objective) One can vary trade off cost between primary or secondary objective accordingly. PARETO FONTS has many optimum solutions where optimum solutions cannot be compared against other
optimum solutions, but all optimum solutions are garanteed to be better than all non-optimum solutions. EXPERIMENTAL RESULTS LEAF performance can be used to compare to other AutoML technique
because LEAF has a clear trade off between performance and time or cost. In Wikipedia Comment Toxicity Classification Domain, The task is to classify toxic comment and non-toxic comment
from 190K example: 93K training, 31K validation, 31Ktest. from the picture, you can see that it is LEAF did progressive better as number of hours increase, and it achieves state of art
performance beating hand crafted (Kaggle Best) after 40 generation or 4619 hours of training. At this point, you may ask yourselves > Can LEAF also minimize the size of these networks
without > sacrificing much in performance? The solutions is multi-objective search, MAXIMIZE FITNESS AND MINIMIZE NETWORK SIZE, LEAF actually converged faster during evolution. As
expected, multiobjective LEAF was also able to DISCOVER NETWORKS WITH FEWER PARAMETERS. Interesting behavior of multi-objective search is that during early generation (10th generation) it
tends to have higher average fitness, but as number of generation increase (40th generation), COST OF TRADE OFF BETWEEN PRIMARY AND SECONDARY OBJECT BECAME OBVIOUS. As a result, the network
in multi-objective search BECAME CONSIDERABLY LESS COMPLEX than ones in single-object search while average fitness PERFORMANCE REMAINS NARROWS between multi-objective search and
single-objective search. I suspect that > the slope between primary and secondary object in Pareto fonts > become STEEPER AS NUMBER OF GENERATION INCREASES. Figure 5: Visualizations of
networks with different complexity discovered by multi-bjective LEAF. The performance of the smaller 56K network (Figure 5a) is nearly as good as that of the larger 125K network (Figure
5b). The smaller network uses only two instances of the module architecture shown in Figure 5c while the larger network uses four instances of the same module. These two networks show that
multi-bjective LEAF is able to find good trade-offs between two conflicting objectives by cleverly using modules. I believe that LEAF could potentially find species, chromosome, and nodes
that consistently perform well across a particular domain of problem. > This is because LEAF can optimize any objective and as one > objective’s trade off become to severe, LEAF could
just hop onto > the next objective and start training again. Maybe by changing objective in circle would help overall result TO CONVERGE FASTER AND ACHIEVE BETTER FITNESS IN ALL
OBJECTIVES (compare to optimizer all objective at once) in recursive fashion. (OBJ1 -> OBJ2 -> OBJ3 -> OBJ1 -> …) Transferring information of one search space to another.







