- Select a language for the TTS:
- UK English Female
- UK English Male
- US English Female
- US English Male
- Australian Female
- Australian Male
- Language selected: (auto detect) - EN
Play all audios:
ABSTRACT Recently, artificial intelligence (AI)-generated resources have gained popularity because of their high effectiveness and reliability in terms of output and capacity to be
customized and broadened, especially in image generation. Traditional Chinese paintings (TCPs) are incomplete because their color contrast is insufficient, and object reality is minimal.
However, combining AI painting (AIP) with TCP remains inadequate and uncertain because of image features such as patterns, styles, and color. Hence, an algorithm named variational
fusion-based fuzzy accelerated painting (VF2AP) has been proposed to resolve this challenge. Initially, the collected TCP data source is applied for preprocessing to convert it into a
grayscale image. Then, the feature extraction process is performed via fuzzy-based local binary pattern (FLBP) and brushstroke patterns to enhance the fusion of intelligent fuzzy logic to
optimize the local patterns of textures in a noisy image. Second, the extracted features are used as inputs to the variational autoencoder (VAE), which is used to avoid latent space
irregularities in the image and the reconstructed image by maintaining minimum reconstruction loss. Third, fuzzy inference rules are applied to avoid variation in the fusion process of the
reconstructed and original images. Fourth, the feedback mechanism is designed with evaluation metrics such as area under the curve-receiver operating characteristic (AUC-ROC) analysis, mean
square error (MSE), structural similarity index (SSIM), and Kullback‒Leibler (KL) divergence to enhance the viewer's understanding of fused painting images. SIMILAR CONTENT BEING VIEWED
BY OTHERS ANCIENT CERAMICS RESTORATION METHOD BASED ON IMAGE PROCESSING TEXTURE STITCHING Article Open access 09 December 2024 ENHANCED MULTIMODAL MEDICAL IMAGE FUSION BASED ON PYTHAGOREAN
FUZZY SET: AN INNOVATIVE APPROACH Article Open access 04 October 2023 UNIVERSALITY AND SUPERIORITY IN PREFERENCE FOR CHROMATIC COMPOSITION OF ART PAINTINGS Article Open access 11 March 2022
INTRODUCTION The use of AI technology enhances creativity and extends the senses of paintings; it has extended the route of cultural growth, improved the expression of creativity, produced
unique layout forms, and provided audiences with an immersive sense of participation. The cross-modality feature of the representation learning process of most AI technologies provides more
autonomy and versatility in exploring new types of painting that would have been unachievable in the past. Establishing a culture of virtuous dynamic human‒computer relationships and
improving the fusion process that introduces evaluation mechanisms to ensure greater prospects for combining AI with artistic endeavors such as paintings, art, and music are necessary. The
best example is Chinese painting, which can serve as an experimental foundation for the digital interpretation and management of basic emotions. Furthermore, crucial problems such as the
extent of AI application in painting production, the essence of art, the value of traditional artworks, and the theme of art creation must be revisited. Interpreting the revisited features
of the paintings and making them into fusion process modifications requires professional judgment, and certain features’ hidden implications may be uncertain. Cultural sensitivity is vital
when combining artistic forms, especially with culturally important forms such as TCP. Sometimes, ensuring that the fusion is appropriate and courteous for the cultural setting can be
difficult. The goal is to develop a fusion method that respects the qualities of both genres and results in paintings that consumers can relate to and understand the intrinsic ambiguities of
creative expression. There is a need for a fuzzy control algorithm to handle these uncertainties, and its ability to accommodate inaccurate and subjective inputs connected to artistic
tastes that match both traditional significance and modern aesthetics is the main advantage of its linguistic terms and membership functions. TCP is a priceless cultural heritage resource
and a distinct visual art style1. In recent years, interest in digitizing TCPs to conserve and revitalize the culture has increased. Computer vision, AI, image extraction, cognitive science,
and painting culture are all used to study AI-based classification and analysis of computer-generated images of Chinese paintings2. The analysis of intelligent art due to the evolution of
AI and art3 has suggested an overlap and fusion process between them. That study demonstrated the way that technology reconstructs and inspires aesthetic development. A multilayer system4
employing empirical machine learning, AI, fuzzy control logic, and other techniques was used to identify actual Chinese paintings based on their images. The most popular method for
determining the authenticity of ancient Chinese paintings is to compare them with comparable paintings. Traditional artwork such as paintings are reproduced with the help of deep learning
techniques5 and follow the feature vectors to improve the quality, low-level and high-level visual elements, and finally, the patterns of paintings. A variant of the art generative
adversarial network (ArtGAN)6 was applied with label information on style, artists, and painting genres to improve the quality of the generated image. By optimizing the pretrained visual
geometry group-fine tunes (VGG-F) model, the image characteristics associated with Chinese paintings are retrieved with improved accuracy and without a digital description system for Chinese
painting emotions7. The sentiment categorization of Chinese paintings was studied via a lightweight convolutional neural network CNN and optimized SqueezeNet with 86% accuracy. However, it
is difficult to recognize different themes and patterns of paintings with the same algorithm8. The study adopts a 3 * 3 image filter to obtain the image edge line by employing the
brushstroke features9 of paintings with the Sobel operator integrated with deep learning. The horn clauses integrated with fuzzy knowledge for logical style painting10 with color dispersions
were analyzed with AI to categorize three different styles of paintings. By establishing boundary limitations, layered deconstruction11 and stroke separation can be achieved to maintain the
style of the original painting. The properties of brushstrokes were retained in the resulting high-relief representation of a painting by inflating and displacing a map of each brushstroke.
The LBP is a texture characteristic frequently utilized in textured bias, facial recognition, painting categories, and other applications. A color picture LBP12 encoding approach based on
color space distance was proposed and can better filter background information. Nevertheless, it could not handle uncertain features related to texture attributes. The goal of image fusion13
is to improve the dimensional accuracy of functional pictures by integrating them into a high-quality structural image. The deep learning model combination of the variation autoencoder and
style GAN (VAE-sGAN) was employed as an image fusion process to generate the blood cell image because of its high-dimensional image representation14. With the unpaired dataset, the
mask-aware GAN15 employed only a single model once. Furthermore, the mask-aware approach was used to make Chinese artwork free to hand. A user-input-based, interactive, and generative method
for automated Chinese Shanshui painting16, in which users are asked to sketch their ideal landscape using only the most basic lines with no artistic training or experience necessary.
However, decoding with the same technique is limited to noniterative binary operations. A fuzzy inference system17 was employed to increase the accuracy of reconstructed computer tomography
(CT) images, especially when the data were inadequate. Combining traditional Chinese painting and AI painting through a fuzzy control algorithm pushes the boundaries of creativity by
integrating cutting-edge technology. Digital art and AI benefit from this novel idea, creating exciting new possibilities in both domains. The main contributions and innovations of this
study are summarized as follows. * 1. The variational fusion-based fuzzy accelerated painting (VF2AP) for combining AI Painting (AIP) with traditional Chinese Painting (TCP) is designed. *
2. This approach provides a consistent feature extraction process via fuzzy methods based on local binary patterns (FLBP) and brushstrokes to enhance the texture patterns of AI paintings. *
3. The approach also handles uncertain latent spaces and generates reconstructed images via VAE with minimal reconstruction loss. * 4. The approach provides an effective feedback mechanism
from users via four metrics, i.e., the area under the curve-receiver operating characteristic (AUC-ROC) analysis, the mean square error (MSE), the structural similarity index (SSIM), and the
Kullback‒Leibler divergence (KL), which are compared with existing approaches and dynamically updated with fuzzy rules. The remainder of the paper is organized as follows. In section
“Literature study”, the literature survey on Chinese painting, the fusion process, and AI painting images integrated with fuzzy concepts is summarized. Section “Research methodology”
introduces the V2FAP algorithm for the fusion process of painting with its learning procedure. In section “Experimental analysis”, the experimental results are discussed, and a comparison of
state-of-the-art approaches is presented. Finally, the conclusions of this research are presented in section “Conclusions”. LITERATURE STUDY Li and Zhang18 designed a multi-instance model
called pyramid overlap with grid division (mPOGD) for generating multi-instance bags from Chinese paintings. To transmit a bag into a conceptual sequence that is ordered and of equal length,
a discriminatory instance is grouped by a sequence generator supported by an LSTM of 1024 neurons with an attention mechanism for classifying Chinese paintings. The Adam optimizer adjusted
the learning rate to 0.001 with 500 epochs. The average running time was 130 s, with 0.13 s per image, an accuracy of 91%, an F1 score of 92.5%, and an AUC of 91.2%. Shen and Yu19 developed
a multibranch attention mechanism network for multifeature fusion (MAM-MFF) and deep semantic modeling of features, an intelligent classification system for Chinese painting artists. AI
alterations to the fundamental notion of art aesthetically in terms of outer space, duration, and logical reasoning were offered, and its aesthetic features of deboundaryization,
submergence, and feelings were analyzed with color, texture, and integration via the VGG16 model. GAN and authentic related processes were also intelligently used for fusion painting
evaluation. Chen et al.20 proposed the fusion process of Thangka and Chinese painting (FTCP) via the Tibetan cycleGAN, which is based on a neural network optimized via the Adam optimizer
with 10.0 and a learning rate of 0.001. The questionnaire selected was in color, visual, and easy to use with rich image quality, style, and effects. The evaluated FIDs were 166.06 and 236
for Thangka paintings. Dong et al.21 employed cross-modal retrieval (CR) to find images of traditional Chinese painting with a fusion of text and image forms. The significance of the text
characteristics was extracted via the BERT model, and the image characteristics were extracted via a convolutional neural network (CNN). They built a new collection of 3528 paintings from
the feature fusion (FF) process with 15K iterations and a 0.01 learning rate, and a gradient descent optimization technique was applied to analyze the gate and residual features. Geng et
al.22 developed a multichannel color fusion network (MCFN) that extracted visual characteristics from various color views and improved AI models’ capacity to capture delicate details and
nuances in Chinese painting by considering several color channels. A regional weighted pooling approach tailored to the DenseNet169 framework improved the mining of highly distinct
characteristics. They reported that a color space accuracy of 98.6% improved the recall, precision, Fl score, and pooling capacity by 94%. DenseNet169 was computationally demanding during
both training and inference. Yang et al.23 proposed a transfer learning framework, CycleGAN-OFR, to investigate the intersection of two classic Chinese cultural heritages, i.e., TCP and
calligraphy, via pretrained ResNet blocks. To increase the creativity of the fused images, one-shot learning (O), parameter freezing (F) with the 0.1 technique, and regularization (R) were
applied. Eighty percent of the input dataset was used to pretrain the model across 200 epochs of 100 generators at a learning rate of 0.0002. The Frechet inception database metric was
evaluated with a score of 369.597 for the fused images. Wang et al.24 suggested a mobile application, the Smart Art System (m-SAS) with (1) a painting detection phase that implemented a
single shot with a painting landmark location to eliminate background features and (2) a recognition phase with ultrahigh classifiers for painting via the fusion of local features. The
results were 95% recognition accuracy of the TCP and latency of 110 ms, with the drawbacks of a certain loss in accuracy and a bad outcome of the prediction box impacting the rectification
model. Li et al.25 applied deep regression pair learning to fuse multifocus images (dRPL-FMI) with binary maps to prevent patch decomposition. Edge preservation and structure similarity
techniques were used in the training process to improve the quality; the Adam optimizer had 20,000 images with a learning rate of 0.001 and 50 iterations. The metrics evaluated were
structure similarity (0.99), mutual information (8.21), average gradient (70.9), edge intensity (6.84), and visual information fidelity (94.6), with a mean peak signal-to-noise ratio of 44%
and a computational complexity of 0.15 s. This study did not include multifocus image matching. Zhang et al.26 proposed infrared-to-visible object mapping (IVOMFuse). To begin, the author
analyzed the infrared picture via the probability-induced intuitionistic fuzzy C-means method (PIIFCM) Then, the author extracted the image's target area based on the attributes of the
image's structure. However, it was impossible to segment it immediately because of the low contrast of the visible picture target. Finally, the author tested fourteen additional best
image fusion algorithms against our technique on three widely used datasets: TNO, CVC14, and RoadScene. This approach won six out of ten assessment measures. Zhou et al.27 recommended the
image registration and robust image fusion method framework for power thermal anomaly detection (Re2FAD). The optimal registration parameters were solved by constructing a criterion function
and then calculating a joint histogram of the source pictures after low-frequency decomposition. The membership function was developed to make the divided areas' labels more
understandable. Third, the label determined the fusion approach to rebuild the fused image. According to the objective evaluation indicators, the suggested technique outperformed the
comparative method by 29.03% when accurately detecting thermal anomalies. With an average running time of only 2.696 s, it could handle auxiliary thermal anomaly detection tasks. Existing
research gaps are discussed in Table 1 as limitations that include inadequate color contrast, low object reality, and ambiguities associated with painting elements such as patterns,
brushstroke styles, and color consistency, which are some of the deficiencies that have been identified. With a feedback mechanism and evaluation metrics, feature extraction mitigates
uncertainties in AIP-TCP fusion via VAE processing and fuzzy inference rules to maintain consistency and improve viewer understandability. Table 1 describes the various algorithms discussed
in the literature, including their data sources, algorithms used, metrics evaluated, and research gaps. The associated work demonstrates that there are extremely few approaches related to
the fusion of traditional and modern paintings with the assistance of fuzzy control. However, existing approaches have several limitations, such as improper edge quality while performing
fusion, poor label accuracy due to loss, poor image feature selection, a lack of multifocus image matching, and an improper data source for TCP. Unexpectedly, with the value of existing
approaches, a lack of uncertainty still exists in computerized painting models. Hence, this study proposes variational fusion-based fuzzy accelerated painting model (VF2AP) for fusing AI
painting (AIP) with traditional Chinese painting (TCP). RESEARCH METHODOLOGY The following sections examine the data source description, training data model, and implementation details. DATA
SOURCE DESCRIPTION The proposed model is analyzed via a dataset acquired from traditional Chinese landscape paintings in several open-access museums28. The input attributes of the data
source are described in Table 1, which contains four categories of image sources with 2192 total Chinese paintings, each with 512 × 512 dimensions. The dataset in this research comprises
2192 traditional Chinese paintings sourced from diverse inputs from open-access museums, including the Princeton University Art Museum, Harvard University Art Museum, Metropolitan Museum of
Art, and Smithsonian’s free gallery of paintings. These paintings are classified into four landscape style categories and stored in a JPEG format. The dataset’s diversity is reflected in the
painting’s content and styles, with each image having dimensions of 512 × 512 pixels. The dataset offers a broad spectrum of traditional Chinese art, allowing for a comprehensive
exploration of various styles and thematic content in the fusion process. Table 2 provides a detailed description of the attributes of the data sources used in this research. The three fuzzy
sets represent the low, medium, and high membership categories in the fuzzy logic parameters of the VF2AP algorithm. Linguistic terms such as traditional, balanced, and modern describe
various datasets. Then, a Gaussian membership function for the medium category and triangle functions for the low and high categories are used. To determine the width of a brushstroke, a
2-pixel threshold is used, and gradient calculations are performed via the Sobel operator with a 3 × 3 kernel. During the fusion process, the weights assigned to the TCP and AIP inputs are
0.6 and 0.4, respectively. Judgments on which features to include or exclude are guided by the 0.7 fusion threshold. A VAE algorithm undergoes 50 training iterations at a learning rate of
0.001 and a batch size of 32 samples at each iteration. The MSE and KL divergence are two loss functions used for reconstruction and latent space regularization, respectively. VARIATIONAL
FUSION-BASED FUZZY ACCELERATED PAINTING (VF2AP) ALGORITHM TCP is a creative reworking of scenes from nature and an additional representation of a natural vision. The method of extracting
compact and relevant patterns from an image is known as feature extraction. The primary goal of feature extraction is to extract the most important information from source or raw data. Fuzzy
sets offer a versatile framework for dealing with the indeterminacy that characterizes real-world systems, which is caused primarily by the imprecise and defective nature of the
information. The original creative thinking of AI has been extensively addressed, with wider implications of AI in traditional art development. However, fuzzy sets can address intuitionistic
indices in images for various reasons, most of which are caused by intrinsic deficiencies in the collection and imaging system process. VAE benefits from quick training, excellent
stability, variation, and enhanced image reconstruction quality. In its latent space, the VAE retains the spirit of TCP brushstrokes. The VAE's latent space brushstroke style is
combined with the LBP features taken from TCP and AI paintings. The fuzzy control algorithm can consider the brushstroke style attributes and the LBP features for dynamic modifications to
AI-generated paintings. Texture-related attributes, together with stroke characteristics, are now taken into account by fuzzy logic rules. The goal is to develop a unified and appealing
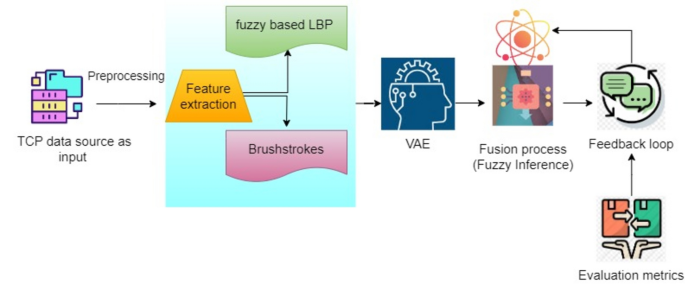
design solution that highlights the distinct characteristics of every style in traditional painting and generates something innovative and original in modern AIP. Figure 1 shows the overall
operation of the VF2AP algorithm for the fusion process of TCP and AIP. Fuzzy control, which uses linguistic rules and membership functions to address uncertainty and imprecision, is a good
fit for VF2AP because it captures the subtle and subjective parts of artistic fusion without relying on strict mathematical formality, which becomes essential when dealing with the
subjective and qualitative nature of artistic styles. Artistic tastes are often accompanied by uncertainty and imprecise bounds, which can be represented via fuzzy logic. Because of its
adaptability and intuitiveness, fuzzy control is a good fit for this study since it can address the subjective and complicated nature of artistic forms. TRADITIONAL CHINESE PAINTING DATA
PREPROCESSING The purpose of preprocessing the TCP is to prepare the raw data for subsequent analysis of features; hence, the TCP source data are first preprocessed to create a grayscale
image. Grayscale conversion creates a single transmit image with grayscale by obtaining the weighted average of the color channels. The intensity levels in the generated grayscale image
range between 0 and 255. Stroke features are the lines that compose an image’s content, and the lines are the fundamental elements that constitute an image’s content. The variety of lines in
the image can express the attitude and shape of the image. Line thickness and storytelling can also transmit distinct information. In Fig. 2, the first diagram (a) represents the attribute
from the Smithsonian of record number 1249. The converted grayscale image is fed into the subsequent feature extraction and VAE process. Similarly, Fig. 2b represents the TCP attribute of
the Harvard group with a record number of 12 for the converted grayscale image representation. FEATURE EXTRACTION Color dissemination, texture sequences, brushstroke techniques, and other
aesthetic characteristics could all be used. The incorporation of texture can also help individuals communicate specific cultural objectives. Learning the color patterns and texture of
Chinese painting results in a comparable atmosphere that maintains the qualities of Chinese paintings and, to some extent, completes cultural expression. * 1. Texture patterns. To extract
texture patterns from TCP and AI-generated paintings, a fuzzy-based LBP is applied to capture textural qualities such as the brushstroke features of each painting style. The function expects
an 8-bit image with grayscale as input. Fuzzy logic is then used to compare both paintings to decide how to fuse both styles. For fusion, fuzzy-based LBP parameters such as the radius and
neighboring points are defined with two fuzzy sets \(X,Y\) for each pixel in the image. The membership of these fuzzy ensembles is pixels in the neighborhood \(n\) that may belong to both
the fuzzy set \(X\) and the fuzzy set \(Y\). (1) Given the area of the radius \(r\) as well as the number of neighboring points \(n\), create a circular neighbor of adjacent pixels \(adj\).
(2) Compare the intensity level of every adjacent pixel to the center pixel. (3) Make a binary code by giving a ‘1’ if the intensity of the adjacent pixel is more or the same and a ‘0’
otherwise. (4) To generate the FLBP pattern associated with the pixel, interpret its binary information α clockwise. The label histogram can then be utilized as a texture descriptor. The
generated LBP codes are used to generate histograms \(H\) that depict the distribution of local texture variations in the images. Here, \(\mu f\left( {X,Y} \right):U \to \left[ {0,1}
\right]\) represents the degree of membership to which the pixel of neighborhood \(p\left( n \right)\) with gray value \(g\left( n \right)\) is greater than or equal to \(p\left( \zeta
\right)\) with the control parameter \(C\), which controls the degree of fuzziness between both sets \(X\) and \(Y\) and can be expressed via Eq. (1) as follows: $$FLBP_{code}^{a,b,h} = \mu
f\left( X \right)\alpha_{x}^{h0} + \mu f\left( Y \right)\alpha_{y}^{h0}$$ (1) The fuzzy control system uses the LBP histograms of TCP and AIP as input variables with \(a\) and \(b\) as the
coordinates of a pixel with x and y ranging from binary bit representations α = 0 to \(n {\text{the}}\) local neighborhoods, and the _0_th histogram bin is represented as _h0_. Fuzzifying
these histograms involves defining linguistic labels (e.g., “Low,” “Medium,” and “High”) and membership criteria \(\mu f\) for the histogram bins. Define fuzzier rules \(R\) that determine
the TCP and AIP influences according to their LBP histograms and generate an array \(A\) of \(R\). The LBP elements and fuzzy analysis findings are utilized to determine which areas of the
images require restoration. The fused painting is created via the changes made through the preceding stage. This result would be a painting with textures and components from TCP- and
AI-generated forms. * 2. Brushstroke extraction. Different brushstrokes present different feelings and are considered important reflections of painting techniques and a natural exile of the
artist's personality, taste, and artistic endowment such that it can be used to distinguish painting styles. From the representation of a grayscale representation of an image, the
gradient of the image in the horizontal direction is calculated via a Scharr operator inspired by the improved version of existing operators. Since it uses 3 × 3 convolution kernels designed
to provide better rational symmetry and sensitivity to diagonal edges, the representation of the gradient matrix is given as \(G_{x}\). The threshold \(T\) is defined to determine the
brushstroke constituents, and the absolute values of the gradient along each row are summed to create a gradient profile \(G\left( \wp \right)\) for an image with the identification of
length (orientation) and width (thickness) via Eq. (2). $$G\left( \wp \right)_{x} = \sum \left| {G_{x} \left( {x,y} \right)} \right| for y in \left[ {0,image\_height} \right]$$ (2) The
stroke orientation, dimension, curves, texture, and other pertinent aspects are analyzed. These properties are transformed into an accurate fusion representation. If \(G\left( \wp
\right)_{x} > T\) for some \(x\) in [0, image_width], then there is a horizontal brushstroke in the image. Find the distance between regions on the opposite side of the stroke across the
perpendicular line to calculate the width of the stroke. Incorporating all the extracted features can render the creative distinctions among the paintings easier to understand and recognize.
The application of this research work appears to focus mainly on texture patterns and brushstroke features, which may result in a low-dimensional space of features. If the total number of
features is moderate and not excessively large, there is probably no compelling reason to minimize complexity via feature selection. Table 3 illustrates and represents the source image
features and brushstroke pattern extraction. TRAINING PHASE OF VAE The VAE architecture, comprising the encoder, latent space block, and decoder modules, is created, as depicted in Fig. 3.
To map TCP images to the latent space, the VAE is trained on the TCP dataset through the encoder module. The loss due to reconstruction is minimized, and the KL divergence term during
training is minimized such that the latent space of a model is consistent and follows a certain distribution, generally Gaussian. We define the functions determining membership for input
characteristics such as fuzzy-based LBP \(H\) bins and brushstroke properties. The linguistic features are the brushstroke length: {low, medium, high} and LBP membership: {short, moderate,
long}. Fuzzy logic helps to specify linguistic variables of painting {traditional, balanced, modern} and membership coefficients that measure the degree to which a particular aesthetic is
present in the fused painting. These linguistic variables capture and express subjective thoughts associated with artistic styles. Block sizes are first dynamically selected by the image
dimensions and used to separate images from traditional Chinese paintings (TCPs) and AI-generated paintings (AIAPs). $$Block_{size} = im_{size} /no.of\, blocks$$ The fuzzy-based LBP feature
extraction approach captures each block’s complex local texture patterns. Language variables such as {low, medium-sized, high} for brushstroke length and {short, moderate, long} for LBP
membership are incorporated into new fuzzy logic rules that specialize in block-level features. The VAE latent space distribution should incorporate block-based features. The block-level
attributes are mixed harmoniously by adjusting the latent space vector (L) via the block-level features. By extracting features block by block from Fig. 3, the algorithm can better identify
variations in the TCP and the AIP. Then, considering features collected from matching TCP and AIP blocks, fuzzy logic inference rules are built at the block level as follows: $$FLBP =
\mathop \sum \limits_{p = 0}^{7} \mu_{f} \left( {I_{p} - I_{c} } \right) \cdot 2^{p}$$ where \(p\) is the index of the neighboring pixels around the center pixel, \(I_{p}\) denotes the
intensity value of the neighboring pixel, \(I_{c}\) represents the intensity value of the central pixel and \(\mu_{f}\) is a fuzzy membership function that determines the degree to which
\(I_{p}\) > \(I_{c}\). The local texture patterns in a noisy image are enhanced via blockwise fuzzy inference. Block-level fusion algorithms such as fuzzy logic, which consider features
retrieved from matching TCP and AIP blocks, are utilized. $$Fused \,\,Block \,\,Output = h\left( {Block \,\,Output_{TCP} ,Block \,\,Output_{AIP} } \right)$$ where \(h\) represents the fusion
function that combines the block outputs from TCP and AIP. The finished fused painting is constructed by combining the outputs of the fused blocks that can be expressed via \(\mathop \sum
\nolimits_{i = 1}^{n} Fused \,\,Block \,\,Output_{i}\). By doing so, it is possible to overcome obstacles caused by differences in painting features and guarantee an optimal fusion of local
patterns and textures. At the block level, fusion occurs, enabling a subtle merging of conventional and AI-generated painting components. To provide individualized and artistic fusion, the
adaptive method with block matching adds flexibility by continuously modifying the inputs of block-based and adaptable approaches according to the painting attributes. The weighted
combination of block and module output aggregation can be defined via \(wt\left( {op} \right)\) as \(wt.block - based - output + \left( {1 - wt} \right)\) with the combination of fused
painting outputs. * (a) Latent space block: Using the LBP histograms and brushstroke characteristics, a collection of fuzzy inference rules is developed. The method in which these fuzzy
constraints influence the mean and variance of the latent space distribution of the VAE is specified. The encoder network maps the original TCP image to a latent variable \(L\), where \(L\)
follows a Gaussian distribution, and the image's attributes match the specified latent variable. The generative process for fusion starts here and is termed \(g\left( L \right),\) which
combines the quality of both TCP and AIP. The function \(g\left( L \right)\) embodies the transformation from a \(L\) to the space of generated artistic painting images \(im\). Since the
latent space vector follows a continuous distribution, it is easy to fine-tune the latent space and generate a more realistic AIP. The objective of VAE is to maximize the variational lower
bound of the marginal likelihood of the fused data. Because the marginal likelihood is frequently unsolvable due to the complexities of creative styles and design, the VAE approximates it
via variational inference by applying a posterior distribution \(q(L|im).\) Fuzzy logic is then applied to the assessment of artistic style and quality of fusion. The VF2AP algorithm ensures
the preservation of the artistic essence of TCP by prioritizing the extraction of texture patterns and brushstroke features. The VAE retains the brushstroke style in the latent space, and
fuzzy logic rules consider nuanced elements such as brushstroke length and LBP membership. Fuzzy logic guides the judgment, reflecting subjectivity and complexities in judging creative
excellence and providing the accurate edge probability of the original input image from TCP; the following Eq. (3) can be used. The evidence of the marginal probability is computed by
integrating all possible values. $$P\left( {im} \right) = \smallint P\left( {im{|}L} \right)*P\left( L \right)dL$$ (3) For the individual data samples, the marginal probability is described
as follows: $$logP\left( {im\left( s \right)} \right) = R_{KL} \left( {q(L|im).||P\left( L \right){ }} \right) + {\mathbb{R}}\left( {en,de\forall im\left( s \right)} \right)$$ (4) where
\(logP\left( {im\left( s \right)} \right)\) represents the loglikelihood of the sample input image \(im\left( s \right)\). In \(R_{KL} \left( {q(L|im).||P\left( L \right){ }} \right)\), the
notation \(R_{KL}\) is calculated via Eq. (4). The entire term represents the KL divergence associated with the latent distribution learning process \(q(L|im)\) and the prior distribution
\(P\left( L \right)\) throughout the latent distribution \(L\). It assesses how closely the approximate posterior matches the previous posterior. By reducing this component, the approximate
posterior is encouraged to be comparable to the prior one, ensuring that \(L\) is well structured. \({\mathbb{R}}\) denotes the reconstruction loss generated or negative error term. It
represents the VAE functionality in the reconstruction process of the given image from the TCP through its \(L\). This is followed by decoding the input data samples back to the fusion
quality with the constraints of fuzzy control parameters \(en\) for encoding and \(de\) for decoding the module for all image samples taken from the TCP. Typically, \(en\) is related to the
encoder network parameters that map the input image to the latent space \(L,\) and \(de\) represents a given sample from the latent space. The decoder system generates an image called AIP in
the data space. * (b) The regularization term (KL divergence) is as follows. The regularization component promotes the latent space probability to adhere to a prior distribution, often a
standard Gaussian distribution. It keeps the latent space well structured and prevents overfitting. This term ensures that the space of latent values is continuous and that the distribution
of points is regular. The Kullback‒Leibler (KL) divergence associated with the latent distribution learning process \(q(L|im)\) and the prior distribution \(P\left( L \right)\) over the
latent variables is used for quantification. It must have an explicit probability distribution, expressed as follows in Eq. (5): $$R_{KL} = - 0.5*\sum \left( {1 + {\text{log}}(var\left( {im}
\right)} \right) - mean\left( {im} \right)^{2} - var\left( {im} \right)$$ (5) $$R_{KL} \left( {org,im} \right) = \mathop \sum \limits_{d = 1}^{N} org\left( d \right)log\left(
{\frac{org\left( d \right)}{{im\left( d \right)}}} \right) \forall { }0 \le {\text{org}},{\text{im}} \le 1$$ (6) In Eq. (6), \(R_{KL}\) defines the regularization term called KL divergence,
\(var\left( m \right)\) represents the variation of the learned distribution for the \(m^{th}\) latent dimension, and the variance of each value in the underlying latent dimension determines
how dispersed they are. The variable \(mean\left( m \right)\) represents the mean of the learned distribution for the same \(m{\text{th}}\) latent dimension. \(org\) represents the
reference image from the TCP, and \(im\) represents the fused image, which represents the histogram probability distributions of the TCP and AIP (reconstructed image). It is a parameter that
the VAE's encoder network learns during training. It determines the distribution center for each underlying latent dimension. * (c) Decoder module for generating a sample image of AIP:
The decoder module represents the reverse process of the input image analyzed in the latent space with the KL divergence condition with the sample input image given in Eq. (7). The
reconstruction loss analyzed from Eq. (8) guarantees that the output image closely matches the initial input information, an important feature in training VAEs. It helps the model acquire
meaningful latent representations of its source data after all the feature representations and allows for fast image generation. $$AIP = Decoder\left( {L\_adjusted} \right)$$ (7) $$Total
\,\,reconstruction_{loss} = MSE + R_{KL}$$ (8) A lower reconstruction loss suggests better reconstruction accuracy, indicating that the VAE correctly captures the key elements of the input
images and produces meaningful outputs. $$MSE = \frac{1}{N \times H \times W}\mathop \sum \limits_{u = 1}^{N} \mathop \sum \limits_{v = 1}^{H} \mathop \sum \limits_{w = 1}^{W} \left(
{org_{uvw} - im_{uvw} } \right)^{2}$$ (9) where \(N,W,H\) represents the number, width, and height of the source image; \(org_{uvw}\) represents the pixel value of the original image at
position \(\left( {u,v,w} \right)\); and \(im_{uvw}\) represents the pixel value of the reconstructed image at the same position. The KL divergence term promotes well-structured latent space
distributions and forms an element of the VAE's regularization process. The optimality includes the hyperparameter setting of the fuzzy control set variables, includes the image
resolution of the input paintings as 512 × 512 pixels throughout evaluation, and allows for an assessment of the algorithms. Additionally, controlling brushstroke extraction settings,
including stroke length (5 px), width (2 px), and varied style, ensures a consistent evaluation of the algorithm response to various artistic features of 2192 artistic styles as data source
input. Regulating the block size in the fusion process is a critical constraint that needs to be observed. The TCP and AIP inputs are given weights of 0.6 and 0.4 throughout the fusion
process. The 0.7 fusion threshold guides decisions about which features to include or reject during the fusion process. After 50 training rounds, a VAE algorithm learns to use a batch size
of 32 samples and a learning rate of 0.001. Without influencing the error rate and uncertainty, the error improvement is evaluated via the MSE. To increase the effectiveness of VF2AP,
techniques for mitigating overfitting, early convergence, and local minima can be considered for further improvement. FUSION PROCESS USING FUZZY INFERENCE Combine the attributes of the TCP
and AI-generated painting based on fuzzy logic modifications. The fusion procedure shown in Fig. 4 strives for a harmonic mixture of cultures that meets the aesthetic criteria. These
approaches produce features that identify specific features or improve the interpretation and resolution of discrepancies. Pixel-level combination, on the other hand, fuses image properties
directly, each pixel by pixel. When the painting images are sparse, the histograms generated from the reconstructed images allow the derivation of the membership functions utilized in fuzzy
systems for inference. Fuzzy Control for Fusion- The fuzzy inference process with the VF2AP algorithm plays a pivotal role in dynamically adjusting AI-generated paintings based on features
extracted from TCP and AI-generated painting inputs from histograms capturing textural qualities from TCP and AIP. The algorithm utilizes Gaussian membership functions through fuzzy control
to define linguistic labels and membership criteria for the histograms obtained from fuzzy-based LBP procedures. Fuzzy rules are then applied to determine the influence of TCP and AIP,
facilitating dynamic adjustments to the AI-generated paintings. The fusion process aims to create a harmonic mixture of cultures, combining TCP and AIP attributes based on fuzzy logic.
Gaussian membership functions represent uncertainties in the distribution of input histograms. Fuzzy rules are applied to combine pixels representing similar features in TCP and AIP,
creating related features in the final fusion result. Moreover, the user feedback loop is collected to fine-tune the fuzzy logic procedures for subsequent fusion with the utilization of
evaluation metrics for continual improvement in preserving the unique artistic qualities of TCP in further enhancement. The input membership functions were generated using the histograms of
the fuzzy-based LBP procedures. A histogram of either of these variables depicts the distribution, with the horizontal plane defining value and the vertical axis indicating the proportion of
each associated with every reconstructed image no. of pixels with a specific value. A Gaussian membership function is utilized because uncertainties tend to follow the distribution. Fuzzy
rules were created to fuse similar image features, such as pixels representing a certain feature in one input image combined with pixels representing a similar feature in the second input
image to make a related feature in the final fusion result. As a defuzzification operator, the Mean of Maximum (MOM) approach is used to assign every one of the pixel values occurring in an
input membership function that corresponds to a centre value that defines an output membership function. $$MOM_{VF2AP} = \frac{{\mathop \sum \nolimits_{x = 1}^{max} C_{x} \cdot \mu f\left( x
\right)}}{{\mathop \sum \nolimits_{x = 1}^{max} \mu f}}$$ (10) From Eq. (10), \(max\) represents the number of membership functions or pixel attributes contributing to the maximum value of
\(\mu f\). The term \(\mu f\) represents the centre value of membership function \(x\). This approach supports the idea that a single grayscale intensity can represent every pixel attribute.
User studies play a vital role in evaluating the success of the VF2AP algorithm in achieving the desired balance in fused paintings and considering a diverse group of participants,
including art enthusiast experts and individuals from the target audience. Through interactive annotation sessions and feedback collection using questionnaires, users provide valuable
insights into the aesthetic values, cultural significance, and overall desired satisfaction with the fusion results. The evaluation includes a compiled set of fused paintings generated by
the VF2AP algorithm for participants to evaluate. This qualitative assessment, coupled with numerical metrics, guides the iterative refinement of the algorithm to align more closely with
user preferences and ensure a harmonious blend of traditional and modern artistic styles. USER INTERACTION AND FEEDBACK LOOP User interaction is used to collect feedback about the fused
painting. Users can submit feedback on changes they want to observe or identify their aesthetic preferences. Annotations of particular elements of the fused paintings, as well as the user’s
aesthetic preferences, are used to gauge the quality of the paintings. Some artistic aspects, such as color palette, brushstroke patterns, or styles, may be preferred by users. Users can
also point out areas that they find particularly appealing or that need improvement. By leveraging fuzzy logic, the VF2AP algorithm may adapt its real-time settings in response to user
input. These data are used to fine-tune the fuzzy logic procedures and variables for subsequent fusion processes, establishing a feedback mechanism based on evaluation metrics such as the
SSIM score, MSE, AUC-ROC, and KL divergence that continually enhances the proposed algorithm. Visitors are first shown both traditional artificial and modern paintings composed by AI. The
experts are then asked if they believe that human or automated models generated the painting. Stability is facilitated by improving the user response to feedback and identifying performance
concerns. Table 4 depicts the two sample models of the TCP as the input and the AI-generated image as the sample output. The summary of these proposed approaches demonstrates that they can
generate distinctive and exceptional fused images. Furthermore, the fusion of artistic styles provides a new route for researching traditional cultural history through AI. The fused images
visually represent human and AI creativity with authentic composition, color, and theme. The VF2AP algorithm strives to be sensitive to cultural norms and ethical concerns, such as
addressing the possible dangers of cultural appropriation when incorporating AI into traditional art forms. The algorithm promotes artist interaction and informed consent, highlights the
importance of traditional art's cultural integrity, and presents artificial intelligence as a tool to enhance human creativity instead of replacing it. The algorithm supports
responsible usage, informs users of cultural importance, and stimulates daily ethical thought to preserve consistency with changing ethical norms and cultural sensitivities. EXPERIMENTAL
ANALYSIS Finally, three comparison models are added to the research investigation to demonstrate the improvement of the proposed strategy with evaluation metrics such as the AUC‒ROC curve.
Evaluation metrics such as AUC-ROC, MSE, SSIM, and KL divergence are implemented to perform a comparative analysis with other existing fusion techniques such as mPOGD18, CR-FF21, and m-SAS25
to highlight the effectiveness of VF2AP. The existing fusion process of the Mpogd18 model is implemented to generate multi-instance bags from Chinese paintings. The fusion process involves
transmitting bags into a conceptual sequence for classification via LSTM with an attention mechanism. Cross-modal retrieval (CR-FF21) is used to find images of traditional Chinese painting
by fusing text and image feature processes. Then, m-SAS25 is employed for painting detection and recognition, in which the application uses a fusion of local features and achieves high
recognition accuracy for TCP. ANALYSIS OF THE AUC‒ROC CURVE The AUC can be utilized as a metric to assess the performance of a system that yields a quality fused output of TCP and AIP
generated from the VAE fusion implementation process with the successful combination of modern styles and aesthetics rather than simply classifying the performance. The fusion process
outcome is a binary classification task to check for successful and unsuccessful fused paintings. The AUC for this ROC curve subsequently quantifies the degree to which the algorithm
differentiates among fused paintings as successful or not. The ROC curve is created by adjusting the decision threshold to identify whether the sample image is successful or unsuccessful.
The encoder component of the VAE is used to retrieve the latent space of the structures of the fused images. This research applies fuzzy control parameters rather than an external binary
classifier to depict the AUC-ROC. Equations (11) and (12) describe the term true positive (TP), which represents the number of successful fusions that are correctly identified as having the
specified level of quality. The term false positive(FP) represents the number of unsuccessful fusions incorrectly identified as having the specified level of quality. True negative (TN)
represents the number of unsuccessful samples correctly identified as not having the specified quality. False negative (FN) represents the number of successful samples incorrectly identified
as not having the fusion quality. $$TPR = TP/\left( {TP + FN} \right)$$ (11) $$FPR = FP/\left( {FP + TN} \right)$$ (12) The AUC that represents the ROC curve shown in Fig. 5 is computed. A
higher AUC suggests better discrimination between classes. A greater AUC score of the proposed VF2AP algorithm indicates improved separateness between effective and unsuccessful fusion
results in the area of latent space. Nevertheless, it may not be directly indicative of the creativity of painting compared with other existing approaches, e.g., mPOGD18, CR-FF21, and
m-SAS25. If the latent form of a fused image attains the necessary thresholds identified through defuzzified quality, then it is labeled a successful and unsuccessful pattern. By plotting
the ROC-AUC curve shown in Fig. 5, the plots show how the model performs at various sensitivity and specificity levels and the rates of false positives and true positives at various decision
thresholds. One important statistic for benchmarking and model selection is the higher ROC-AUC score, which often shows superior discrimination abilities and seems better than supplementary
accuracy metrics. ANALYSIS OF MSE DURING TRAINING LOSS The model's parameters are randomly initialized at the start of the training phase of the VAE in the latent space domain. The MSE
is anticipated to be relatively high, and the output images may not yet resemble the input data. The decoder phase \(de\) learns to create images corresponding to the input data as the VAE
trains, resulting in a decrease in the MSE. MSE reduction implies that the model’s ability to recreate the input images accurately is improving. The relationship between MSE reduction and
image quality after fusing is examined. The model then determines whether the decrease in the MSE corresponds to improved conformance with the fuzzy control criteria and the desired quality
of fusion. The number of iterations is set to 100 epochs during the training phase; hence, \(L\) is set to train the TCP image feed into the extracted features and generate the qualified AI
model painting of the reconstructed image. From Fig. 6, it is possible to visually observe the reestablished images at various training phases in addition to the MSE analysis calculated from
Eq. (9) concerning the artist's evaluation handled by fuzzy membership control behavior in the inference rule. The relationship between MSE reduction and image quality after fusing is
examined. As the MSE decreases, the model becomes more adept at mimicking the design and attributes associated with the TCP and AIP. For each iteration, the value of the MSE is monitored. If
it continues to fall and stabilize, the model converges and locates an accurate portrayal of the source image. STRUCTURAL SIMILARITY INDEX (SSIM) The SSIM score is a quality evaluation
index built around the mathematical representation of three terms, multiplication, brightness, contrast, and structure, to improve the quality of an image presented in the painting. With
respect to structural features, the SSIM can be used to analyze how both styles fuse. The SSIM is calculated for every combination of fused paintings (original TCP + AI-fused) to assess
their structural similarity via Eq. (13) as follows: $$SSIM\left( {org,im} \right) = \frac{{\left( {2m_{org} m_{im} + \beta_{1} } \right).\left( {2var_{org,im} + \beta_{2} }
\right)}}{{\left( {m_{org}^{2} + m_{im}^{2} + \beta_{1} } \right)\left( {var_{org}^{2} + var_{im}^{2} + \beta_{2} } \right)}}$$ (13) where \(org\) and \(im\) are the original TCP, fused
means reconstructed images; \(m_{org}\) and \(m_{im}\) are the mean values of the original and fused images, respectively; \(var_{org}\) and \(var_{im}\) are the variances of both images;
and \(\beta_{1}\) and \(\beta_{2} { }\) are constants added for numerical stability. To optimize the fusion process, the SSIM results illustrated in Fig. 7 are utilized as feedback. If the
SSIM scores are poor, it could suggest that the fusion is not sufficient for expressing the structural features of the source styles. Experts must be involved in providing substantial input
on the fused paintings. Monitoring how the SSIM scores evolve throughout iterations or epochs is important. A rising trend implies that the VAE is gradually enhancing its capacity for
creating fused images that are structurally comparable to the original images. SSIM scores range from 0 (no resemblance) to 1 (perfect resemblance). KL DIVERGENCE ANALYSIS Relative entropy
(RE), called the Kullback‒Leibler (KL) divergence, is a quantitative measure that compares two sets of probabilities. It can be used to calculate the difference in statistical significance
between two image distributions of pixel values. The KL divergence is used to assess the distinction among the pixel value patterns of the TCP and AIP produced by the VAE. Obtaining a KL
divergence of 0 corresponds to precisely conserving both artistic styles while conforming to the artistic standards established by the fuzzy inference method. Only ten image samples are
analyzed in the graph below to enable more efficient use of resources such as storage, computing power, and memory within a given iteration count. In particular, it emphasizes the importance
of completing a comprehensive and rigorous examination of the ten painting image samples to ensure that the outcomes are accurate and useful. This strategy can be used to lay a solid base
before scaling up. Figure 8 shows that a lower KL divergence implies that the pixel value distribution in the fused photos is more comparable to the distribution in the source images,
implying that the fusion method effectively captures the statistical features of both styles. Outliers and variations in infrequent events can make the KL divergence sensitive. It may fail
to represent perceptual changes between images accurately. The result allows the quantification of how much the fused images respond to the artistic guidelines specified by the fuzzy
controlling procedure. SENSITIVITY ANALYSIS The optimal weights are found when the VF2AP model has been trained with the links and patterns discovered in the training dataset, which are
captured by these weights. The next step is to save the model to a file with its design and the best weights in PyTorch. Predictions on fresh data or sensitivity study into the effects of
changing input painting image attributes on model output are possible with the loaded model. To calibrate the model, adjust its parameters, and do a study of the sensitivity observed, the
ability to alter input features systematically and how it affects the model’s predictions is shown in Fig. 9. The trained VF2AP model’s optimal weight database is used in the fuzzy inference
process to make real-time adjustments to AI-generated paintings using fuzzy control parameters; this way, learnt patterns are considered for better results. Experimental results on TCP
datasets support the efficiency and superiority of the proposed approach over other state-of-the-art techniques. The experiment results reveal that the fusion images with the proposed
approach are high quality and visually appealing. CONCLUSIONS By combining traditional Chinese paintings (TCPs) with artificial intelligence (AI)-generated paintings (AIPs), the variational
fusion-based fuzzy accelerated painting (VF2AP) technique shows promise in overcoming the shortcomings of TCPs. To create fused paintings that compensate for TCP's shortcomings in
object reality and color contrast, VF2AP meticulously employs preprocessing, feature extraction, the VAE training phase, and a fuzzy inference model. The system features a feedback loop for
user involvement and continual improvement, and it innovatively combines traditional and AI methods. The diversity of the dataset, which includes 2192 paintings from multiple sources, helps
the algorithm handle differing styles more robustly. Although VF2AP has potential, it should be improved and studied more, especially with respect to the loss function, semantic
understanding, and time-related elements of cultural adaptability. This study paves the way for an algorithmic approach to painting that honors the spirit of classical Chinese painting while
using the possibilities of AIP. POTENTIAL LIMITATIONS The VAE model relies on texture patterns and brushstroke features, which are limitations in capturing deeper semantic or conceptual
aspects of artistic styles. There is potential for improvement by exploring the integration of advanced neural network architectures or external feature extraction processes to enhance the
algorithm’s ability to represent more complex artistic attributes and achieve a more nuanced fusion of traditional and modern painting styles. FUTURE ENHANCEMENTS The integration of
augmented reality for interactive experiences, improvements in real-time applications, and exploration of multimodal art fusion are all potential directions for future research. Ethical
concerns, user-driven customization, and cultural preservation all play a role in the thoughtful and responsible development of the VF2AP algorithm. Future improvements may involve refining
the algorithm with a hybrid loss function, integrating semantic understanding for better cultural adaptation, creating transferable cultural knowledge models, implementing an interactive
user interface, developing adaptive mechanisms for dynamic cultural influence, extending to cross-domain artistic style transfers, and defining multimodal cultural evaluation metrics.
VF2AP’s requirement for a single resolution may make it difficult to process varied image sources, a major pitfall when faced with different input resolutions of sample paintings. The
accuracy of the algorithm's matching and fusing capabilities may be impaired when the images provided have substantially different qualities or resolutions. Recognizing this constraint
and considering ways to improve the algorithm to handle different image resolutions or altered information would make it more resilient to diverse inputs in the future scope of this
research. DATA AVAILABILITY The datasets used and/or analysed during the current study available from the corresponding author on reasonable request. REFERENCES * Zhang, W. _et al_.
Computational approaches for traditional Chinese painting: From the “six principles of painting” perspective. arXiv preprint arXiv:2307.14227 (2023). * Yang, D., Ye, X. & Guo, B.
Application of multitask joint sparse representation algorithm in Chinese painting manoimage classification. _Complexity_ 2021, 1–11 (2021). ADS Google Scholar * Zheng, X., Bassir, D.,
Yang, Y. & Zhou, Z. Intelligent art: The fusion growth of artificial intelligence in art and design. _Int. J. Simul. Multidiscipl. Design Optimiz._ 13, 24 (2022). Article ADS Google
Scholar * Chen, W., Yu, Y. & Zhu, P. Design and research of Chinese painting authenticity identification system based on image recognition. In _International Conference on Innovative
Computing_ 103–109 (Springer Nature, 2023). * Castellano, G. & Vessio, G. Deep learning approaches to pattern extraction and recognition in paintings and drawings: An overview. _Neural
Comput. Appl._ 33(19), 12263–12282 (2021). Article Google Scholar * Tan, W. R., Chan, C. S., Aguirre, H. E. & Tanaka, K. Improved ArtGAN for conditional synthesis of natural images and
artwork. _IEEE Trans. Image Process._ 28(1), 394–409 (2018). Article ADS MathSciNet Google Scholar * Chen, B. Classification of artistic styles of Chinese art paintings based on the CNN
model. _Comput. Intell. Neurosci._ 2022, 4520913 (2022). PubMed PubMed Central Google Scholar * Bian, J. & Shen, X. Sentiment analysis of Chinese paintings based on lightweight
convolutional neural network. _Wirel. Commun. Mobile Comput._ 2021, 1–8 (2021). Google Scholar * Qiao, L., Guo, X. & Li, W. Classification of Chinese and Western painting images based
on brushstrokes feature. In _Entertainment Computing–ICEC 2020: 19th IFIP TC 14 International Conference, ICEC 2020, Xi'an, China, November 10–13, 2020, Proceedings 19_ 325–337
(Springer International Publishing, 2020). * Costa Bueno, V. _Fuzzy Horn Clauses in Artificial Intelligence: A Study of Free Models, and Applications in Art Painting Style Categorization_
(Universitat Autònoma de Barcelona, 2021). * Fu, Y., Yu, H., Yeh, C. K., Zhang, J. & Lee, T. Y. High relief from brush painting. _IEEE Trans. Visual. Comput. Graph._ 25(9), 2763–2776
(2018). Article Google Scholar * Zhao, Q. Research on the application of local binary patterns based on color distance in image classification. _Multimedia Tools Appl._ 80(18), 27279–27298
(2021). Article Google Scholar * Biswas, B. & Sen, B. K. Medical image fusion using type-2 fuzzy and near-fuzzy set approach. _Int. J. Comput. Appl._ 42(4), 399–414 (2020). Google
Scholar * Liu, K., Shuai, R. & Ma, L. Cells image generation method based on VAE-SGAN. _Procedia Comput. Sci._ 183, 589–595 (2021). Article Google Scholar * Wang, Y., Zhang, W. &
Chen, P. ChinaStyle: A Mask-Aware Generative Adversarial network for Chinese traditional image translation. In _SIGGRAPH Asia 2019 Technical Briefs_ 5–8 (2019). * Zhou, L., Wang, Q. F.,
Huang, K. & Lo, C. H. An interactive and generative approach for Chinese shanshui painting document. In _2019 International Conference on Document Analysis and Recognition (ICDAR)_
819–824 (IEEE, 2019). * Malik, V. & Hussein, E. M. A fuzzy inference method for image fusion/refinement of CT images from incomplete data. _Heliyon_ 7(4), e06839 (2021). Article PubMed
PubMed Central Google Scholar * Li, D. & Zhang, Y. Multi-Instance learning algorithm based on LSTM for Chinese painting image classification. _IEEE Access_ 8, 179336–179345 (2020).
Article Google Scholar * Shen, Y. & Yu, F. The influence of artificial intelligence on art design in the digital age. _Sci. Program._ 2021, 1–10 (2021). Google Scholar * Chen, Y.,
Wang, L., Liu, X. & Wang, H. Artificial intelligence-empowered art education: A cycle-consistency network-based model for creating the fusion works of Tibetan painting styles.
_Sustainability_ 15(8), 6692 (2023). Article Google Scholar * Dong, Z. _et al_. Feature fusion based cross-modal retrieval for traditional Chinese painting. In _2020 International
Conference on Culture-oriented Science & Technology (ICCST)_ 383–387 (IEEE, 2020). * Geng, J. _et al._ Mccfnet: Multi-channel color fusion network for cognitive classification of
traditional chinese paintings. _Cogn. Comput._ 2023, 1–12 (2023). Google Scholar * Yang, Z. _et al_. Pacanet: A study on Cyclegan with transfer learning for diversifying fused Chinese
painting and calligraphy. arXiv preprint arXiv:2301.13082 (2023). * Wang, Z. _et al._ SAS: Painting detection and recognition via smart art system with mobile devices. _IEEE Access_ 7,
135563–135572 (2019). Article Google Scholar * Li, J. _et al._ DRPL: Deep regression pair learning for multi-focus image fusion. _IEEE Trans. Image Process._ 29, 4816–4831 (2020). Article
ADS Google Scholar * Zhang, X., Liu, G., Huang, L., Ren, Q. & Bavirisetti, D. P. IVOMFuse: An image fusion method based on infrared-to-visible object mapping. _Dig. Signal Process._
137, 104032 (2023). Article Google Scholar * Zhou, X. _et al._ Re2FAD: A differential image registration and robust image fusion method framework for power thermal anomaly detection.
_Optik_ 259, 168817 (2022). Article Google Scholar * Chinese Landscape Painting Dataset. https://www.kaggle.com/. (2023, accessed 25 Aug 2023).
https://www.kaggle.com/datasets/myzhang1029/chinese-landscape-painting-dataset. Download references AUTHOR INFORMATION AUTHORS AND AFFILIATIONS * College of International Business and
Economics, WTU, Wuhan, 430200, China Xu Xu Authors * Xu Xu View author publications You can also search for this author inPubMed Google Scholar CONTRIBUTIONS Xu xu write and revise the
article. CORRESPONDING AUTHOR Correspondence to Xu Xu. ETHICS DECLARATIONS COMPETING INTERESTS The author declares no competing interests. ADDITIONAL INFORMATION PUBLISHER'S NOTE
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations. RIGHTS AND PERMISSIONS OPEN ACCESS This article is licensed under a
Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as
long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not
have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s
Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not
permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit
http://creativecommons.org/licenses/by-nc-nd/4.0/. Reprints and permissions ABOUT THIS ARTICLE CITE THIS ARTICLE Xu, X. A fuzzy control algorithm based on artificial intelligence for the
fusion of traditional Chinese painting and AI painting. _Sci Rep_ 14, 17846 (2024). https://doi.org/10.1038/s41598-024-68375-x Download citation * Received: 21 February 2024 * Accepted: 23
July 2024 * Published: 01 August 2024 * DOI: https://doi.org/10.1038/s41598-024-68375-x SHARE THIS ARTICLE Anyone you share the following link with will be able to read this content: Get
shareable link Sorry, a shareable link is not currently available for this article. Copy to clipboard Provided by the Springer Nature SharedIt content-sharing initiative KEYWORDS * Fuzzy
control * Artificial intelligence * Fusion process * Traditional Chinese painting * Fuzzy inference * Variation autoencoder








