- Select a language for the TTS:
- UK English Female
- UK English Male
- US English Female
- US English Male
- Australian Female
- Australian Male
- Language selected: (auto detect) - EN
Play all audios:
ABSTRACT _Meghimatium bilineatum_ is a notorious pest land slug used as a medicinal resource to treat ailments in China. Although this no-model species is unique in terms of their ecological
security and medicinal value, the genome resource of this slug is lacking to date. Here, we used the Illumina, PacBio, and Hi-C sequencing techniques to construct a chromosomal-level genome
of _M. bilineatum_. With the Hi-C correction, the sequencing data from PacBio system generated a 1.61 Gb assembly with a scaffold N50 of 68.08 Mb, and anchored to 25 chromosomes. The
estimated assembly completeness at 91.70% was obtained using BUSCO methods. The repeat sequence content in the assembled genome was 72.51%, which mainly comprises 34.08% long interspersed
elements. We further identified 18631 protein-coding genes in the assembled genome. A total of 15569 protein-coding genes were successfully annotated. This genome assembly becomes an
important resource for studying the ecological adaptation and potential medicinal molecular basis of _M. bilineatum_. SIMILAR CONTENT BEING VIEWED BY OTHERS HAPLOTYPE-RESOLVED
CHROMOSOMAL-LEVEL GENOME ASSEMBLY OF BUZHAYE (MICROCOS PANICULATA) Article Open access 15 December 2023 A CHROMOSOMAL-LEVEL GENOME ASSEMBLY OF _BEGONIA FIMBRISTIPULA_ (BEGONIACEAE) Article
Open access 12 March 2025 CHROMOSOME-LEVEL GENOME ASSEMBLY OF THE TRADITIONAL MEDICINAL PLANT _LINDERA AGGREGATA_ Article Open access 03 April 2025 BACKGROUND & SUMMARY The _Meghimatium
bilineatum_ (_syn. Philomycus bilineatus_ Benson, 1842) is a member of the Philomycidae family and is a notorious quarantine pest land slug that can cause enormous damage to commercial
crops, horticultural crops, grasslands, and forests in East Asia1,2,3,4,5. It has a strong ecological adaptation to terrestrial environments and has been widely distributed in various
regions of China6. It does not only feed on stems, leaves, fruits, or juices of plants causing direct economic losses but also secretes mucus and excretes feces contaminating fruits and
vegetables. This contamination results in a reduction in the market value of products and transmits diseases. Thus, it poses great harm to local agricultural productivity and ecological
security, resulting in substantial economic and ecosystem losses7. However, from another perspective, _M. bilineatum_ also exhibits medicinal properties. For example, its crude extracts are
used in the treatment of bacterial-induced infectious diseases, the polysaccharides in slug cell are used as natural antioxidants to prevent cancer, and the antimicrobial peptide derived
from the slug is utilized to combat skin infections caused by _Candida albicans_8,9,10. At present, some researchers have carried out in-depth studies on the pharmacological effects of slug
extract, indicating that slugs can be used as a valuable medicinal resource with development and application value9,10. Thus, the study of slug species is very meaningful. In addition to its
ecological threat and medicinal value, _M. bilineatum_, as a member of 30000 described terrestrial gastropod mollusks with shell-less, has completed the transition from aquatic to
terrestrial. Similar to other slug species, they have developed many various robust features, including a pulmonate for breathing air, a sophisticated neural-immune system, and the ability
to produce mucus to adapt to the terrestrial environments11,12,13. However, compared with land snails, land slugs display unique life strategy for terrestrial environments, such as defense
by secreting mucus including specific chemical compounds and better mobility under predation, because they have no protective shell1,14. Furthermore, shell-less land slugs do not expend
energy ingesting large amounts of calcium, enabling them to grow faster. Although land slugs have strong adaptation mechanism, their evolutionary history remains unclear. In recent years,
molecular phylogenetics analysis of land slugs of the genus _Meghimatium_ based on the mitogenome and nuclear loci has offered new perspectives into the taxonomic revisions and evolution of
these species15,16,17. However, these studies cannot fully explain the molecular mechanism of wide ecological adaptation information and the potential genetic basis of medicinal resource
traits of this slug. Furthermore, the Philomycidae slug genomics have yet to be published. Therefore, assembling a genome of this slug species should be urgently assembled. The study of
genomes in certain terrestrial mollusks, has shown advancements, including the release of genomic data for two land snails, _Achatina fulica_ and _Pomacea canaliculata_. However, thorough
investigations into the evolutionary mechanisms associated with terrestrial adaptation remain scant18,19. Recently, one genome study of _Achatina immaculata_, namely giant African snail has
verified that some genes related to respiratory system, dormancy system, and immune system have undergone great expansion to adapt to the terrestrial environments20. However, to date,
high-quality genomic resources for land slugs are rarely reported. The land slugs and snails, as terrestrial gastropod mollusks with or without shell protection, have different biological
processes related to their terrestrial lifestyle. Hence, assembling a genome of the land slug species would facilitate intensive study of this species’ adaptive evolution. Herein, we
assembled the genome of _M. bilineatum_ by uniting the sequencing techniques of Illumina, PacBio, and Hi-C. Three methods, including _ab initio_ gene prediction, homolog and RNA-Seq-based
prediction, were used to perform genomic annotation. In addition, the comparative genomics analysis of _M. bilineatum_ and 11 other distantly related species were performed. This study
offers insights for the effective management and utilization of slug populations and provides valuable genome information into the evolutionary history and genetic mechanisms of this
important gastropod group. METHODS LAND SLUG COLLECTING AND SEQUENCING Adult land slugs _M. bilineatum_ were collected from a wild area in Zhoushan, Zhejiang, China (122.212 E, 29.979 N).
Total DNA was extracted from whole body of the land slug _M. bilineatum_ using the SDS-based extraction method. Then, the DNA samples were purified using QIAGEN® Genomic kit (QIAGEN,
Germany) for genome sequencing. First, Illumina short-read library with insert sizes of 300–350 bp was generated, and was sequenced using the Illumina Novaseq. 6000 platform. Second, PacBio
HiFi-read library with insert sizes of 10–40 kb was generated using SMRTbell Express Template Prep Kit 2.0 (Pacific Biosciences, USA) and sequenced using the PacBio Sequel II platform.
Finally, Hi-C short-read library was generated using the purified DNA from the whole body of _M. bilineatum_ according to the previously performed protocol by Belton _et al_. with given
adjustments; it was sequenced using the Illumina Novaseq. 6000 platform21. A total of 250.12 Gb of clean Illumina short-reads, 71.33 Gb HiFi CCS reads and 140.69 Gb clean Hi-C reads were
obtained (Table 1). Total RNA was isolated from whole body of the land slug using TRIzol reagent (Invitrogen, MA, USA) for transcriptome sequencing. The RNA-seq library was generated using
NEBNext® Ultra™ RNA Library Prep Kit (NEB, USA) and sequenced using the Illumina Novaseq. 6000 platform. The RNA-seq reads were used for genome annotation. A total of 21.79 Gb of clean data
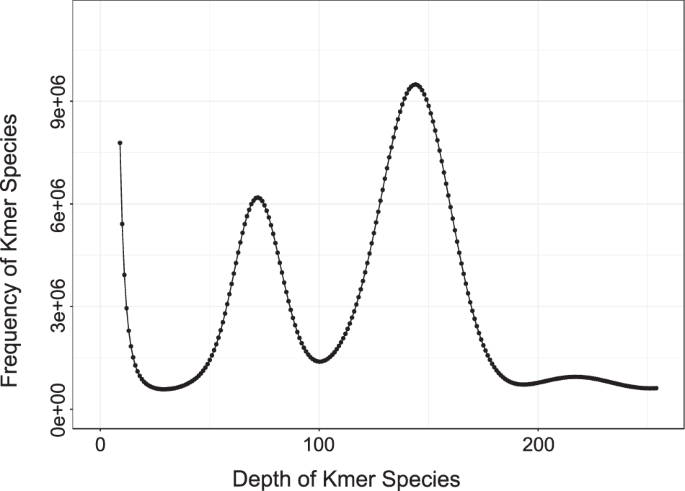
was obtained (Table 1). GENOME SIZE ESTIMATION Based on 250.12 Gb clean Illumina short-reads, the genome size, heterozygosity and repetitive sequence content was determined using the k-mer
analysis with GCE (1.0.0) following the default parameter22. A total of 223,346,880,670 k-mers with a depth of 144 was obtained (Fig. 1). In addition, the genome size of _M. bilineatum_ was
approximately 1.5 Gb, with a heterozygosity of 1.05% and proportion of repeat sequences at 43.69%. CHROMOSOMAL-LEVEL GENOME ASSEMBLY In the initial genome assembly, HiFiasm (v0.16.0) method
was used for _ab initio_ to assemble the genome using the HiFi reads from PacBio23. This preliminary assembly yielded a genome size of 1.80 Gb (Table 2). Subsequently, the redundant
sequences were filtered out using Purge_Haplotigs (v1.0.4) software with the parameter of cutoff ‘-a 70 -j 80 -d 200’24. Based on PacBio sequencing data, a 1.63 Gb contig-level genome
assembly of _M. bilineatum_ was obtained, and 2526 contigs displayed contig N50 and N90 sizes of 1.37 and 320.449 Mb, respectively (Table 2). The chromosome-level assembly of _M. bilineatum_
was conducted using Hi-C technology. Initially, Bowtie2 (v2.3.4.3) following the default parameters was used to match the 140.69 Gb clean Hi-C reads to the contig-level genome to obtain
unique mapped paired-end reads25. A total of 185.36 million paired-end reads were uniquely mapped (Table S1), of which 88.02% represented valid pairs (Table S2). Subsequently, contigs were
assembled into the chromosome-level scaffolds using the 3D-DNA processes (v180922) (parameters: -r 0) with all valid pairs, and the JuiceBox (v1.11.08) was used to correct the errors in the
genome assembly26,27. We anchored and obtained 25 pseudo-chromosomes with seven unanchored scaffolds. The 25 pseudo-chromosomes covering ~99.95% of the final genome with size ranging from
25.66 Mb to 135.71 Mb (Fig. 2; Table 3). Ultimately, we obtained a 1.61 Gb chromosomal-level genome assembly of _M. bilineatum_ with contig N50 size and scaffold N50 size of 1.36 Mb and
68.08 Mb, respectively. Genome assembly results showed that the genome size of _M. bilineatum_ is similar to that of the Spanish slug _Arion vulgaris_ (1.54 Gb) in the previous study28.
REPEAT-CONTENT IDENTIFICATION AND CLASSIFICATION Repetitive sequences, including tandem repeats and interspersed repeats, in _M. bilineatum_ genome were determined using the _de novo_
prediction and homolog-based methods. Based on homology comparison, RepeatMasker (open-4.0.9) (parameters: default) and RepeatProteinMask (parameters: default) software were utilized to find
the interspersed repeats against the RepBase database (http://www.girinst.org/repbase)29. On the basis of _de novo_ prediction, TRF (v4.09) software (parameters: default) was used to
identify the tandem repeats30. In addition, a repetitive sequence library was constructed using the RepeatModeler (open-1.0.11) with default parameters and LTR-FINDER_parallel (v1.0.7) with
default parameters31,32. Then, the RepeatMasker (open-4.0.9) with default parameters was used to identify the repeat element against this repeat library31. After combining the results from
_de novo_ prediction and homolog-based methods, we identified and classified 1.18 Gb of repetitive sequences, taking up 72.51% of the assembled genome, mainly including 7.99% DNA elements,
34.08% long interspersed elements (LINE), and 16.35% unknown sequences (Tables 4 & 5). The repeat-content in the _M. bilineatum_ genome is similar to the Spanish slug _A. vulgaris_
(75.09%), and is higher than other studied gastropod species28,33. These results further validate the accuracy of our genome assembly. IDENTIFICATION AND ANNOTATION OF PROTEIN-CODING GENES
First, we used repeat-masked genome sequences to perform _ab initio_ gene prediction, and then used AUGUSTUS (v3.3.2), Genscan (v1.0) and GlimmerHMM (v3.0.4) software to detect the
protein-coding genes34,35,36. Second, to conduct homology-based prediction, protein sequences from _Candidula unifasciata_ (GCA_905116865.2), _Elysia chlorotica_ (GCA_003991915.1), _Haliotis
rubra_ (GCA_003918875.1), _Haliotis rufescens_ (GCA_023055435.1), _Lottia gigantea_ (GCA_000327385.1), _Pakobranchus ocellatus_ (GCA_019648995.1), and _Pomacea canaliculate_
(GCA_003073045.1) were compared with the _M. bilineatum_ genome utilizing TBLASTN (v2.2.29) (e-value ≤ 1e-5) to determine candidate regions, and further used GenWise (v2.4.1) software to
accurately map the screened proteins to the _M. bilineatum_ genome to obtain splice sites37. Third, to perform transcriptome sequencing-based prediction, the RNA-seq reads from Illumina were
mapped to the _M. bilineatum_ genome by using the TopHat (v2.1.1) software following default arguments, and the transcripts were assembled using Cufflinks (v2.2.1) software with the “-e 100
-C” parameter38,39, and the protein-coding genes were determined using the PASA (v2.3.2)40. Fourth, using the MAKER2 (v2.31.10) and HiFAP software following default parameters, we combined
the three predictions to construct a complete and nonredundant reference gene database41. Finally, in the _M. bilineatum_ genome, 18631 identified protein-coding genes were found. The length
of the average gene, including CDS, exon, and intron, is presented in Table 6. These predicted gene structures were also compared with the seven other homologous species (Fig. 3). We
annotated these protein-coding genes functions through the alignment of gene sequences to the InterPro, GO, KEGG, SwissProt, TrEMBL, TF, Pfam, NR, and KOG database by using BLAST + (2.11.0)
software (e-value ≤ 1e-5)42,43,44,45,46,47. In addition, based on InterPro database and Pfam database, the conserved protein domain and motif associated with the function annotated was
determined using the InterProScan tool (v5.61-93.0) with the “-seqtype p -formats TSV -goterms -pathways -dp” parameter48. Ultimately, a total of 15569 genes (83.57%) were successfully
annotated (Table 7). IDENTIFICATION OF NON-CODING GENES The tRNA, rRNA, miRNA, and snRNA non-coding RNAs are not translated into proteins. In the annotation process of non-coding RNAs,
tRNAscan-SE (v1.3.1) software following the default parameters was used to find the tRNA sequences in the assembled genome according to the structural characteristics of tRNA49. BLASTN was
applied to identify rRNA genes in the assembled genome according to the highly conserved characteristics of rRNA. In addition, according to the covariance model of Rfam database (v14.8), we
used the INFERNAL program with default arguments to predict the miRNA and snRNA sequences50. Finally, 1424 rRNAs, 941 tRNAs, 588 snRNAs, and 49 miRNAs were annotated (Table 8). COMPARATIVE
GENOMIC ANALYSIS The single-copy ortholog genes of _M. bilineatum_ and 11 other molluscan species (Table S3), including _Nautilus pompilius_, _Octopus minor_, _Bathymodiolus platifrons_,
_Chrysomallon squamiferum_, _Elysia chlorotica_, _Biomphalaria glabrata_, _Candidula unifasciata_, _Pomacea canaliculate_, _Haliotis rubra_, _Gigantopelta aegis_ and _Lottia gigantea_, were
determined using the “-l 1.5” parameter of hcluster_sq software from OrthoMCL (v2.0.9) to validate the phylogenetic relationships among the 12 molluscan species51. A total of 29157 gene
families were determined, including 671 common orthologous gene families and 135 single-copy gene families, in the 12 molluscan species (Fig. 4; Table S4). The MAFFT (v7.487) software with
default parameters was used to compare the single-copy genes52. All conserved sequences in the single-copy genes were extracted using Gblock (v0.91b) software with the “-t = c” parameter53.
Subsequently, the ML phylogenetic tree was constructed using the “-f a -N 100 -m GTRGAMMA” parameter of RAxML (v8.2.12)54, with _N. pompilius_ and _O. minor_ as the outgroup. Moreover, the
divergence time of the 12 mollusks were estimated using the MCMCtree (v4.4) program in software PAML (v4.9) with “clock = 3; model = 0” parameter according to the calibration times of _N.
pompilius_-_B. platifrons_ (619.1–527.6 MYA), _B. platifrons_-_P. canaliculata_ (541.7–463.4 MYA), _N. pompilius_-_O. minor_ (452.6–364.2 MYA), _B. glabrata_-_P. canaliculata_ (496.0–310.0
MYA) and _G. aegis_-_C. squamiferum_ (100.0–42.4 MYA) from the Timetree database55. The evolutionary tree showed that _M. bilineatum_ and _C. unifasciata_ were clustered together, and
diverged ~231.4 MYA (Fig. 5). We also identified the expanded genes and contracted gene families in the 12 mollusks using CAFE (v5.0.0) with the “-p 0.05 -t 4 -r 10000” parameter56. The
result showed that there were 879 expanded gene families and 1385 contracted gene families in the _M. bilineatum_ (Fig. 5). DATA RECORDS All sequencing data from three sequencing platforms
have been uploaded to the NCBI SRA database (transcriptomic sequencing data: SRR2586702857, genomic Illumina sequencing data: SRR2590398958, genomic PacBio sequencing data: SRR2591904459 and
SRR2591904360, Hi-C sequencing data: SRR2591915561 and SRR2591915462). The final chromosome-level assembled genome file has been uploaded to the GenBank database under the accession
JAXGFX00000000063. Genome annotation files (including repeat-content annotation, gene structure annotation, gene functional annotation and non-coding genes annotation) have been uploaded to
the Figshare database64. TECHNICAL VALIDATION EVALUATING QUALITY OF THE DNA AND RNA Prior to the genome sequencing, we used the NanoDrop 2000 Spectrophotometer (Thermo Fisher Scientific, San
Jose, CA, USA) and Qubit 3.0 Fluorometer (Thermo Fisher Scientific, San Jose, CA, USA) to determine the quality (OD260/280 and OD260/230) and concentration of the DNA and RNA samples to
ensure the accuracy of sequencing data. We also used the agarose gel electrophoresis and Agilent 2100 Bioanalyzer (Agilent Technologies, Palo Alto, California, USA) to determine the
integrity of the DNA and RNA samples. EVALUATING QUALITY OF THE GENOME ASSEMBLY To evaluate the sequence consistency and assembly quality, the BWA (v0.7.17-r1188) and Minimap2
(v2.24_x64-linux) software were used to map the short reads from Illumina and HiFi reads from PacBio to the assembled genome, respectively65,66. After these processes, 99.35% of the short
reads from Illumina and 99.62% of the HiFi reads from PacBio were aligned, covering 99.81% and 99.99% of the assembled genome, respectively (Table S5 & S6). Moreover, BUSCO (v5.4.3)
analysis was conducted to evaluate the assembly quality based on the mollusca_odb10 database67. A total of 91.70% of the 5295 single-copy orthologs in the assembled genome were determined as
complete, including 4015 single-copy (75.80%) and 842 duplicated (15.90%), 0.89% and 7.46% of the total single-copy orthologs were fragmented and missing, respectively (Table 9). EVALUATING
QUALITY OF THE GENOME ANNOTATION BUSCO (v5.4.3) analysis was conducted to evaluate the genome annotation quality based on the mollusca_odb10 database67. A total of 91.60% of the 5295
single-copy ortholog genes in the assembled genome were determined as complete, including 3912 single-copy genes (73.90%) and 939 duplicated genes (17.70%), 1.30% and 7.10% of the total
genes were fragmented and missing, respectively (Table 9). CODE AVAILABILITY No specific code was used in this study. The standard bioinformatic tools were used for data analysis.
Furthermore, the parameter setting of the bioinformatics tools was performed in accordance with the manual and protocols and described in the Methods Section. REFERENCES * Barker, G. _The
biology of terrestrial molluscs_. 1–146 (CABI Wallingford UK, 2001). * Tsai, C.-L. & Wu, S.-K. A new _Meghimatium_ slug (Pulmonata: Philomycidae) from Taiwan. _Zool. Stud._ 47, 759–766
(2008). Google Scholar * Orians, C. M., Fritz, R. S., Hochwender, C. G., Albrectsen, B. R. & Czesak, M. E. How slug herbivory of juvenile hybrid willows alters chemistry, growth and
subsequent susceptibility to diverse plant enemies. _Ann. Bot._ 112, 757–765 (2013). Article PubMed PubMed Central Google Scholar * Park, G.-M. A new species and a new record of
_Meghimatium_ Slugs (Pulmonata: Philomycidae) in Korea. _J. Environ. Biol._ 39, 399–405 (2021). Google Scholar * Xu, Z. W., Wang, X. F., Wei, X. M. & Shi, H. Ecological observation on
_Phiolomycus bilineatus_ and preliminery study on its damage control. _Chin. J. Zool_ 2, 5–8 (1993). Google Scholar * Wiktor, A., De-Niu, C. & Ming, W. Stylommatophoran slugs of China
(Gastropoda: Pulmonata)-Prodromus. _Folia Malacol_ 8, 3–35 (2000). Article Google Scholar * Dong, Y. H., Qian, J. R. & Xu, P. J. Occurrence law of _Philomycus bilineatus_ and its
prevention. _Acta Agric. Jiangxi_ 20, 37–38 (2008). Google Scholar * Li, Z., Yuan, Y., Meng, M., Hu, P. & Wang, Y. De novo transcriptome of the whole-body of the gastropod mollusk
_Philomycus bilineatus_, a pest with medical potential in China. _J. Appl. Genet._ 61, 439–449 (2020). Article CAS PubMed Google Scholar * He, R., Ye, J., Zhao, Y. & Su, W. Partial
characterization, antioxidant and antitumor activities of polysaccharides from _Philomycus bilineatus_. _Int. J. Biol. Macromol_ 65, 573–580 (2014). Article CAS PubMed Google Scholar *
Li, Z. _et al_. _In vitro_ and _in vivo_ activity of phibilin against Candida albicans. _Front. Microbiol._ 13, 862834 (2022). Article PubMed PubMed Central Google Scholar * Hiong, K.
C., Loong, A. M., Chew, S. F. & Ip, Y. K. Increases in urea synthesis and the ornithine–urea cycle capacity in the Giant African Snail, _Achatina fulica_, during fasting or aestivation,
or after the injection with ammonium chloride. _J. Exp. Zool. A Comp. Exp. Biol._ 303, 1040–1053 (2005). Article PubMed Google Scholar * Mukherjee, S., Sarkar, S., Munshi, C. &
Bhattacharya, S. The uniqueness of _Achatina fulica_ in its evolutionary success. in _Organismal and Molecular Malacology_ (ed. Ray, S.) 219–232 (IntechOpen, 2017). * Rosenberg, G. A new
critical estimate of named species-level diversity of the recent Mollusca. _Am. Malacol. Bull._ 32, 308–322 (2014). Article Google Scholar * Ponder, W. & Lindberg, D. R. _Phylogeny and
Evolution of the Mollusca_. (University of California Press, 2008). * Yang, T. _et al_. The complete mitochondrial genome sequences of the _Philomycus bilineatus_ (Stylommatophora:
Philomycidae) and phylogenetic analysis. _Genes_ 10, 198 (2019). Article CAS PubMed PubMed Central Google Scholar * Xie, G.-L. _et al_. A novel gene arrangement among the
Stylommatophora by the complete mitochondrial genome of the terrestrial slug _Meghimatium bilineatum_ (Gastropoda, Arionoidea). _Mol. Phylogenet. Evol._ 135, 177–184 (2019). Article PubMed
Google Scholar * Ito, S. _et al_. Taxonomic insights and evolutionary history in East Asian terrestrial slugs of the genus _Meghimatium_. _Mol. Phylogenet. Evol._ 182, 107730 (2023).
Article CAS PubMed Google Scholar * Liu, C. _et al_. The genome of the golden apple snail _Pomacea canaliculata_ provides insight into stress tolerance and invasive adaptation.
_Gigascience_ 7, giy101 (2018). Article PubMed PubMed Central ADS Google Scholar * Guo, Y. _et al_. A chromosomal-level genome assembly for the giant African snail _Achatina fulica_.
_Gigascience_ 8, giz124 (2019). Article PubMed PubMed Central Google Scholar * Liu, C. _et al_. Giant African snail genomes provide insights into molluscan whole‐genome duplication and
aquatic–terrestrial transition. _Mol. Ecol. Resour._ 21, 478–494 (2021). Article CAS PubMed Google Scholar * Belton, J.-M. _et al_. Hi–C: a comprehensive technique to capture the
conformation of genomes. _Methods_ 58, 268–276 (2012). Article CAS PubMed Google Scholar * Liu, B. H. _et al_. Estimation of genomic characteristics by analyzing K-mer frequency in de
novo genome projects. _Quant. Biol_ 35, 62–67 (2013). Google Scholar * Cheng, H., Concepcion, G. T., Feng, X., Zhang, H. & Li, H. Haplotype-resolved de novo assembly using phased
assembly graphs with hifiasm. _Nat. Methods_ 18, 170–175 (2021). Article CAS PubMed PubMed Central Google Scholar * Roach, M. J., Schmidt, S. A. & Borneman, A. R. Purge Haplotigs:
allelic contig reassignment for third-gen diploid genome assemblies. _BMC Bioinformatics_ 19, 1–10 (2018). Article Google Scholar * Langmead, B. & Salzberg, S. L. Fast gapped-read
alignment with Bowtie 2. _Nature methods_ 9, 357–359 (2012). Article CAS PubMed PubMed Central Google Scholar * Dudchenko, O. _et al_. De novo assembly of the _Aedes aegypti_ genome
using Hi-C yields chromosome-length scaffolds. _Science_ 356, 92–95 (2017). Article CAS PubMed PubMed Central ADS Google Scholar * Durand, N. C. _et al_. Juicebox provides a
visualization system for Hi-C contact maps with unlimited zoom. _Cell Syst_ 3, 99–101 (2016). Article CAS PubMed PubMed Central Google Scholar * Chen, Z., Doğan, Ö., Guiglielmoni, N.,
Guichard, A. & Schrödl, M. Pulmonate slug evolution is reflected in the de novo genome of _Arion vulgaris_ Moquin-Tandon, 1855. _Sci. Rep._ 12, 14226 (2022). Article CAS PubMed PubMed
Central ADS Google Scholar * Jurka, J. _et al_. Repbase Update, a database of eukaryotic repetitive elements. _Cytogenet. Genome Res._ 110, 462–467 (2005). Article CAS PubMed Google
Scholar * Benson, G. Tandem repeats finder: a program to analyze DNA sequences. _Nucleic Acids Res_ 27, 573–580 (1999). Article CAS PubMed PubMed Central Google Scholar * Price, A. L.,
Jones, N. C. & Pevzner, P. A. De novo identification of repeat families in large genomes. _Bioinformatics_ 21, i351–i358 (2005). Article CAS PubMed Google Scholar * Ou, S. &
Jiang, N. LTR_FINDER_parallel: parallelization of LTR_FINDER enabling rapid identification of long terminal repeat retrotransposons. _Mobile DNA_ 10, 1–3 (2019). Article Google Scholar *
Gomes-dos-Santos, A., Lopes-Lima, M., Castro, L. F. C. & Froufe, E. Molluscan genomics: The road so far and the way forward. _Hydrobiologia_ 847, 1705–1726 (2019). Article Google
Scholar * Stanke, M. _et al_. AUGUSTUS: ab initio prediction of alternative transcripts. _Nucleic Acids Res_ 34, W435–W439 (2006). Article CAS PubMed PubMed Central Google Scholar *
Majoros, W. H., Pertea, M. & Salzberg, S. L. TigrScan and GlimmerHMM: two open source ab initio eukaryotic gene-finders. _Bioinformatics_ 20, 2878–2879 (2004). Article CAS PubMed
Google Scholar * Burge, C. & Karlin, S. Prediction of complete gene structures in human genomic DNA. _J. Mol. Biol._ 268, 78–94 (1997). Article CAS PubMed Google Scholar * Birney,
E., Clamp, M. & Durbin, R. GeneWise and GenomeWise. _Genome Res_ 14, 988–995 (2004). Article CAS PubMed PubMed Central Google Scholar * Trapnell, C. _et al_. Transcript assembly and
quantification by RNA-Seq reveals unannotated transcripts and isoform switching during cell differentiation. _Nat. Biotechnol._ 28, 511–515 (2010). Article CAS PubMed PubMed Central
Google Scholar * Kim, D. _et al_. TopHat2: accurate alignment of transcriptomes in the presence of insertions, deletions and gene fusions. _Genome Biol_ 14, 1–13 (2013). Article Google
Scholar * Haas, B. J. _et al_. Improving the _Arabidopsis_ genome annotation using maximal transcript alignment assemblies. _Nucleic Acids Res_ 31, 5654–5666 (2003). Article CAS PubMed
PubMed Central Google Scholar * Holt, C. & Yandell, M. MAKER2: an annotation pipeline and genome-database management tool for second-generation genome projects. _BMC Bioinformatics_
12, 1–14 (2011). Article Google Scholar * McGinnis, S. & Madden, T. L. BLAST: at the core of a powerful and diverse set of sequence analysis tools. _Nucleic Acids Res_ 32, W20–W25
(2004). Article CAS PubMed PubMed Central Google Scholar * Apweiler, R. _et al_. UniProt: the universal protein knowledgebase. _Nucleic Acids Res_ 32, D115–D119 (2004). Article CAS
PubMed PubMed Central Google Scholar * Finn, R. D. _et al_. InterPro in 2017—beyond protein family and domain annotations. _Nucleic Acids Res_ 45, D190–D199 (2017). Article CAS PubMed
Google Scholar * Kanehisa, M. _et al_. Data, information, knowledge and principle: back to metabolism in KEGG. _Nucleic Acids Res_ 42, D199–D205 (2014). Article CAS PubMed Google Scholar
* Tatusov, R. L. _et al_. The COG database: an updated version includes eukaryotes. _BMC Bioinformatics_ 4, 1–14 (2003). Article Google Scholar * Bairoch, A. _et al_. The SWISS-PROT
protein knowledgebase and its supplement TrEMBL in 2003. _Nucleic Acids Res_ 31, 365–370 (2003). Article PubMed PubMed Central Google Scholar * Zdobnov, E. M. & Apweiler, R.
InterProScan–an integration platform for the signature-recognition methods in InterPro. _Bioinformatics_ 17, 847–848 (2001). Article CAS PubMed Google Scholar * Lowe, T. M. & Eddy,
S. R. tRNAscan-SE: a program for improved detection of transfer RNA genes in genomic sequence. _Nucleic Acids Res_ 25, 955–964 (1997). Article CAS PubMed PubMed Central Google Scholar *
Griffiths-Jones, S. _et al_. Rfam: annotating non-coding RNAs in complete genomes. _Nucleic Acids Res_ 33, D121–D124 (2005). Article CAS PubMed Google Scholar * Li, L., Stoeckert, C. J.
& Roos, D. S. OrthoMCL: identification of ortholog groups for eukaryotic genomes. _Genome Res_ 13, 2178–2189 (2003). Article CAS PubMed PubMed Central Google Scholar * Nakamura,
T., Yamada, K. D., Tomii, K. & Katoh, K. Parallelization of MAFFT for large-scale multiple sequence alignments. _Bioinformatics_ 34, 2490–2492 (2018). Article CAS PubMed PubMed
Central Google Scholar * Talavera, G. & Castresana, J. Improvement of phylogenies after removing divergent and ambiguously aligned blocks from protein sequence alignments. _Syst.
Biol._ 56, 564–577 (2007). Article CAS PubMed Google Scholar * Stamatakis, A. RAxML version 8: a tool for phylogenetic analysis and post-analysis of large phylogenies. _Bioinformatics_
30, 1312–1313 (2014). Article CAS PubMed PubMed Central Google Scholar * Yang, Z. PAML 4: phylogenetic analysis by maximum likelihood. _Mol. Biol. Evol._ 24, 1586–1591 (2007). Article
CAS PubMed Google Scholar * Mendes, F. K., Vanderpool, D., Fulton, B. & Hahn, M. W. CAFE 5 models variation in evolutionary rates among gene families. _Bioinformatics_ 36, 5516–5518
(2020). Article CAS Google Scholar * _NCBI Sequence Read Archive_ https://identifiers.org/ncbi/insdc.sra:SRR25867028 (2023). * _NCBI Sequence Read Archive_
https://identifiers.org/ncbi/insdc.sra:SRR25903989 (2023). * _NCBI Sequence Read Archive_ https://identifiers.org/ncbi/insdc.sra:SRR25919044 (2023). * _NCBI Sequence Read Archive_
https://identifiers.org/ncbi/insdc.sra:SRR25919043 (2023). * _NCBI Sequence Read Archive_ https://identifiers.org/ncbi/insdc.sra:SRR25919155 (2023). * _NCBI Sequence Read Archive_
https://identifiers.org/ncbi/insdc.sra:SRR25919154 (2023). * Sun, S. L., Han, X. L., Han, Z. Q. & Liu, Q. _Meghimatium bilineatum_, whole genome shotgun sequencing project. _GenBank_
https://identifiers.org/ncbi/insdc:JAXGFX000000000 (2023). * Sun, S. L. Chromosomal-scale genome assembly and annotation of the land slug (_Meghimatium bilineatum_). _figshare_
https://doi.org/10.6084/m9.figshare.24038871.v1 (2023). * Li, H. & Durbin, R. Fast and accurate short read alignment with Burrows–Wheeler transform. _Bioinformatics_ 25, 1754–1760
(2009). Article CAS PubMed PubMed Central Google Scholar * Li, H. Minimap2: pairwise alignment for nucleotide sequences. _Bioinformatics_ 34, 3094–3100 (2018). Article CAS PubMed
PubMed Central Google Scholar * Simão, F. A., Waterhouse, R. M., Ioannidis, P., Kriventseva, E. V. & Zdobnov, E. M. BUSCO: assessing genome assembly and annotation completeness with
single-copy orthologs. _Bioinformatics_ 31, 3210–3212 (2015). Article PubMed Google Scholar Download references ACKNOWLEDGEMENTS This work was supported by the Zhejiang Provincial Natural
Science Foundation of China (LR21D060003) and the Introduction of Talent Research Start-up Fund of Zhejiang Ocean University (JX6311031923). AUTHOR INFORMATION AUTHORS AND AFFILIATIONS *
Fishery College, Zhejiang Ocean University, Zhoushan, Zhejiang, 316022, China Shaolei Sun, Xiaolu Han & Zhiqiang Han * Wuhan Onemore-tech Co., Ltd, Wuhan, Hubei, 430076, China Qi Liu
Authors * Shaolei Sun View author publications You can also search for this author inPubMed Google Scholar * Xiaolu Han View author publications You can also search for this author inPubMed
Google Scholar * Zhiqiang Han View author publications You can also search for this author inPubMed Google Scholar * Qi Liu View author publications You can also search for this author
inPubMed Google Scholar CONTRIBUTIONS Z.Q.H. designed the project. S.L.S., X.L.H. and Q.L. collected the samples and analyzed the data. S.L.S. and Z.Q.H. wrote the manuscript. S.L.S., Z.Q.H.
and Q.L. revised the manuscript. All authors read and approved the final version of the manuscript. CORRESPONDING AUTHORS Correspondence to Zhiqiang Han or Qi Liu. ETHICS DECLARATIONS
COMPETING INTERESTS The authors declare no competing interests. ADDITIONAL INFORMATION PUBLISHER’S NOTE Springer Nature remains neutral with regard to jurisdictional claims in published maps
and institutional affiliations. SUPPLEMENTARY INFORMATION SUPPLEMENTARY INFORMATION OF CHROMOSOMAL-SCALE GENOME ASSEMBLY AND ANNOTATION OF THE LAND SLUG (_MEGHIMATIUM BILINEATUM_) RIGHTS
AND PERMISSIONS OPEN ACCESS This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in
any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The
images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not
included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly
from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. Reprints and permissions ABOUT THIS ARTICLE CITE THIS ARTICLE Sun, S., Han, X.,
Han, Z. _et al._ Chromosomal-scale genome assembly and annotation of the land slug (_Meghimatium bilineatum_). _Sci Data_ 11, 35 (2024). https://doi.org/10.1038/s41597-023-02893-7 Download
citation * Received: 08 September 2023 * Accepted: 27 December 2023 * Published: 05 January 2024 * DOI: https://doi.org/10.1038/s41597-023-02893-7 SHARE THIS ARTICLE Anyone you share the
following link with will be able to read this content: Get shareable link Sorry, a shareable link is not currently available for this article. Copy to clipboard Provided by the Springer
Nature SharedIt content-sharing initiative


:max_bytes(150000):strip_icc():focal(649x0:651x2)/beyonce-lisa-bonet-tout-3a5d67f5e366499e869175fadaa3e674.jpg)


