- Select a language for the TTS:
- UK English Female
- UK English Male
- US English Female
- US English Male
- Australian Female
- Australian Male
- Language selected: (auto detect) - EN
Play all audios:
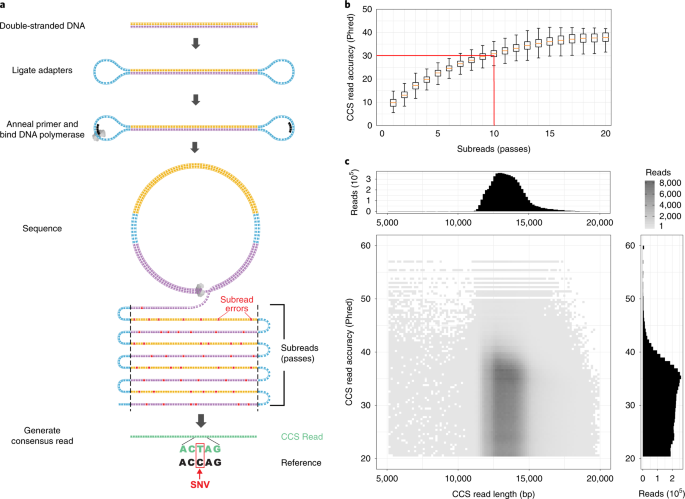
ABSTRACT The DNA sequencing technologies in use today produce either highly accurate short reads or less-accurate long reads. We report the optimization of circular consensus sequencing
(CCS) to improve the accuracy of single-molecule real-time (SMRT) sequencing (PacBio) and generate highly accurate (99.8%) long high-fidelity (HiFi) reads with an average length of 13.5
kilobases (kb). We applied our approach to sequence the well-characterized human HG002/NA24385 genome and obtained precision and recall rates of at least 99.91% for single-nucleotide
variants (SNVs), 95.98% for insertions and deletions <50 bp (indels) and 95.99% for structural variants. Our CCS method matches or exceeds the ability of short-read sequencing to detect
small variants and structural variants. We estimate that 2,434 discordances are correctable mistakes in the ‘genome in a bottle’ (GIAB) benchmark set. Nearly all (99.64%) variants can be
phased into haplotypes, further improving variant detection. De novo genome assembly using CCS reads alone produced a contiguous and accurate genome with a contig N50 of >15 megabases
(Mb) and concordance of 99.997%, substantially outperforming assembly with less-accurate long reads. Access through your institution Buy or subscribe This is a preview of subscription
content, access via your institution ACCESS OPTIONS Access through your institution Access Nature and 54 other Nature Portfolio journals Get Nature+, our best-value online-access
subscription $29.99 / 30 days cancel any time Learn more Subscribe to this journal Receive 12 print issues and online access $209.00 per year only $17.42 per issue Learn more Buy this
article * Purchase on SpringerLink * Instant access to full article PDF Buy now Prices may be subject to local taxes which are calculated during checkout ADDITIONAL ACCESS OPTIONS: * Log in
* Learn about institutional subscriptions * Read our FAQs * Contact customer support SIMILAR CONTENT BEING VIEWED BY OTHERS TRADEOFFS IN ALIGNMENT AND ASSEMBLY-BASED METHODS FOR STRUCTURAL
VARIANT DETECTION WITH LONG-READ SEQUENCING DATA Article Open access 19 March 2024 EFFICIENT HYBRID DE NOVO ASSEMBLY OF HUMAN GENOMES WITH WENGAN Article Open access 14 December 2020 BEYOND
ASSEMBLY: THE INCREASING FLEXIBILITY OF SINGLE-MOLECULE SEQUENCING TECHNOLOGY Article 09 May 2023 DATA AVAILABILITY Data are available in NCBI BioProject PRJNA529679. CCS reads are available
on NCBI SRA with accession code SRX5327410. Small variant calls are available on NCBI dbSNP with accession codes ss3783301452–ss3798736595. Structural variant calls are available on NCBI
dbVar with accession nstd167. The trio binned Canu assemblies are available on NCBI Assembly with accession codes GCA_004796485.1 (maternal) and GCA_004796285.1 (paternal). Alignments to
GRCh37 are available at ftp://ftp-trace.ncbi.nlm.nih.gov/giab/ftp/data/AshkenazimTrio/HG002_NA24385_son/PacBio_CCS_15kb/ or https://bit.ly/2RW1b3I. Additional data, including all assemblies
and a track hub for the UCSC Genome Browser, are available at https://downloads.pacbcloud.com/public/publications/2019-HG002-CCS. CODE AVAILABILITY Custom scripts are available at
https://github.com/PacificBiosciences/hg002-ccs/. Google DeepVariant, a model trained on PacBio CCS reads, and instructions for use are available at https://github.com/google/deepvariant.
REFERENCES * _DNA Sequencing Costs: Data_ (National Human Genome Research Institute, accessed 7th December 2018); https://www.genome.gov/27541954/dna-sequencing-costs-data/ * Sanger, F.,
Nicklen, S. & Coulson, A. R. DNA sequencing with chain-terminating inhibitors. _Proc. Natl Acad. Sci. USA_ 74, 5463–5467 (1977). CAS Google Scholar * Smith, L. M. et al. Fluorescence
detection in automated DNA sequence analysis. _Nature_ 321, 674–679 (1986). Article CAS Google Scholar * Lander, E. S. et al. Initial sequencing and analysis of the human genome. _Nature_
409, 860–921 (2001). Article CAS Google Scholar * Venter, J. C. et al. The sequence of the human genome. _Science_ 291, 1304–1351 (2001). Article CAS Google Scholar * Mouse Genome
Sequencing Consortium. et al. Initial sequencing and comparative analysis of the mouse genome. _Nature_ 420, 520–562 (2002). Article Google Scholar * Arabidopsis Genome Initiative.
Analysis of the genome sequence of the flowering plant Arabidopsis thaliana. _Nature_ 408, 796–815 (2000). Article Google Scholar * Ronaghi, M., Karamohamed, S., Pettersson, B., Uhlén, M.
& Nyrén, P. Real-time DNA sequencing using detection of pyrophosphate release. _Anal. Biochem._ 242, 84–89 (1996). Article CAS Google Scholar * Bentley, D. R. et al. Accurate whole
human genome sequencing using reversible terminator chemistry. _Nature_ 456, 53–59 (2008). Article CAS Google Scholar * Shendure, J. et al. Accurate multiplex polony sequencing of an
evolved bacterial genome. _Science_ 309, 1728–1732 (2005). Article CAS Google Scholar * McKernan, K. J. et al. Sequence and structural variation in a human genome uncovered by short-read,
massively parallel ligation sequencing using two-base encoding. _Genome Res._ 19, 1527–1541 (2009). Article CAS Google Scholar * Drmanac, R. et al. Human genome sequencing using
unchained base reads on self-assembling DNA nanoarrays. _Science_ 327, 78–81 (2010). Article CAS Google Scholar * Rothberg, J. M. et al. An integrated semiconductor device enabling
non-optical genome sequencing. _Nature_ 475, 348–352 (2011). Article CAS Google Scholar * Sedlazeck, F. J., Lee, H., Darby, C. A. & Schatz, M. C. Piercing the dark matter:
bioinformatics of long-range sequencing and mapping. _Nat. Rev. Genet._ 19, 329–346 (2018). Article CAS Google Scholar * Chaisson, M. J. P. et al. Resolving the complexity of the human
genome using single-molecule sequencing. _Nature_ 517, 608–611 (2015). Article CAS Google Scholar * Seo, J.-S. et al. De novo assembly and phasing of a Korean human genome. _Nature_ 538,
243–247 (2016). Article CAS Google Scholar * Cretu Stancu, M. et al. Mapping and phasing of structural variation in patient genomes using nanopore sequencing. _Nat. Commun._ 8, 1326
(2017). Article Google Scholar * Chaisson, M. J. P. et al. Multi-platform discovery of haplotype-resolved structural variation in human genomes. _Nat. Commun._ 10, 1784 (2019). Article
Google Scholar * Eid, J. et al. Real-time DNA sequencing from single polymerase molecules. _Science_ 323, 133–138 (2009). Article CAS Google Scholar * Mikheyev, A. S. & Tin, M. M. Y.
A first look at the Oxford Nanopore MinION sequencer. _Mol. Ecol. Resour._ 14, 1097–1102 (2014). Article CAS Google Scholar * Jain, M. et al. Nanopore sequencing and assembly of a human
genome with ultra-long reads. _Nat. Biotechnol._ 36, 338–345 (2018). Article CAS Google Scholar * Travers, K. J., Chin, C.-S., Rank, D. R., Eid, J. S. & Turner, S. W. A flexible and
efficient template format for circular consensus sequencing and SNP detection. _Nucleic Acids Res._ 38, e159 (2010). Article Google Scholar * Loomis, E. W. et al. Sequencing the
unsequenceable: expanded CGG-repeat alleles of the fragile X gene. _Genome Res._ 23, 121–128 (2013). Article CAS Google Scholar * Hebert, P. D. N. et al. A sequel to Sanger: amplicon
sequencing that scales. _BMC Genomics_ 19, 219 (2018). Article Google Scholar * Zook, J. M. et al. Extensive sequencing of seven human genomes to characterize benchmark reference
materials. _Sci. Data_ 3, 160025 (2016). Article CAS Google Scholar * Zook, J. M. et al. An open resource for accurately benchmarking small variant and reference calls. _Nat. Biotechnol._
37, 561–566 (2019). Article CAS Google Scholar * Myers, G. In _Algorithms in Bioinformatics_ (eds Brown, D. & Morgenstern, B.) 52–67 (Springer, 2014). * Mandelker, D. et al.
Navigating highly homologous genes in a molecular diagnostic setting: a resource for clinical next-generation sequencing. _Genet. Med._ 18, 1282–1289 (2016). Article CAS Google Scholar *
Ambardar, S., Gowda, M. & High-Resolution Full-Length, H. L. A. Typing method using third generation (Pac-Bio SMRT) sequencing technology. _Methods Mol. Biol._ 1802, 135–153 (2018).
Article CAS Google Scholar * DePristo, M. A. et al. A framework for variation discovery and genotyping using next-generation DNA sequencing data. _Nat. Genet._ 43, 491–498 (2011). Article
CAS Google Scholar * Luo, R., Sedlazeck, F. J., Lam, T.-W. & Schatz, M. C. A multi-task convolutional deep neural network for variant calling in single molecule sequencing. _Nat.
Commun._ 10, 998 (2019). Article Google Scholar * Poplin, R. et al. A universal SNP and small-indel variant caller using deep neural networks. _Nat. Biotechnol._ 36, 983–987 (2018).
Article CAS Google Scholar * Patterson, M. et al. WhatsHap: Weighted haplotype assembly for future-generation sequencing reads. _J. Comput. Biol._ 22, 498–509 (2015). Article CAS Google
Scholar * Sedlazeck, F. J. et al. Accurate detection of complex structural variations using single-molecule sequencing. _Nat. Methods_ 15, 461–468 (2018). Article CAS Google Scholar *
Li, H. Minimap2: pairwise alignment for nucleotide sequences. _Bioinformatics_ 34, 3094–3100 (2018). Article CAS Google Scholar * Chen, X. et al. Manta: rapid detection of structural
variants and indels for germline and cancer sequencing applications. _Bioinformatics_ 32, 1220–1222 (2016). Article CAS Google Scholar * Rausch, T. et al. DELLY: structural variant
discovery by integrated paired-end and split-read analysis. _Bioinformatics._ 28, i333–i339 (2012). Article CAS Google Scholar * Garcia, S. et al. Linked-Read sequencing resolves complex
structural variants. Preprint at _bioRxiv_ https://doi.org/10.1101/231662 (2017). * Chin, C.-S. et al. Phased diploid genome assembly with single-molecule real-time sequencing. _Nat.
Methods_ 13, 1050–1054 (2016). Article CAS Google Scholar * Koren, S. et al. Canu: scalable and accurate long-read assembly via adaptive k-mer weighting and repeat separation. _Genome
Res._ 27, 722–736 (2017). Article CAS Google Scholar * Ruan, J. & Li, H. Fast and accurate long-read assembly with wtdbg2. Preprint at _bioRxiv_ https://doi.org/10.1101/530972 (2019).
* Koren, S. et al. De novo assembly of haplotype-resolved genomes with trio binning. _Nat. Biotechnol._ 36, 1174–1182 (2018). Article CAS Google Scholar * Fungtammasan, A. &
Hannigan, B. How well can we create phased, diploid, human genomes?: An assessment of FALCON-Unzip phasing using a human trio. Preprint at _bioRxiv_ https://doi.org/10.1101/262196 (2018). *
Chin, C.-S. et al. Nonhybrid, finished microbial genome assemblies from long-read SMRT sequencing data. _Nat. Methods_ 10, 563–569 (2013). Article CAS Google Scholar * Vollger, M. R. et
al. Long-read sequence and assembly of segmental duplications. _Nat. Methods_ 16, 88–94 (2019). Article CAS Google Scholar * Schneider, V. A. et al. Evaluation of GRCh38 and de novo
haploid genome assemblies demonstrates the enduring quality of the reference assembly. _Genome Res._ 27, 849–864 (2017). Article CAS Google Scholar * Krusche, P. et al. Best practices for
benchmarking germline small-variant calls in human genomes. _Nat. Biotechnol._ 37, 555–560 (2019). Article CAS Google Scholar * 1000 Genomes Project Consortium. A global reference for
human genetic variation. _Nature_ 526, 68–74 (2015). Article Google Scholar * Quinlan, A. R. BEDTools: The Swiss-Army Tool for Genome Feature Analysis. _Curr. Protoc. Bioinforma._ 47(11),
12.1–34 (2014). Google Scholar * Robinson, J., Soormally, A. R., Hayhurst, J. D. & Marsh, S. G. E. The IPD-IMGT/HLA Database—new developments in reporting HLA variation. _Hum. Immunol._
77, 233–237 (2016). Article CAS Google Scholar * Cleary, J. G. et al. Comparing variant call files for performance benchmarking of next-generation sequencing variant calling pipelines.
Preprint at _bioRxiv_ https://doi.org/10.1101/023754 (2015). * Li, H. et al. A synthetic-diploid benchmark for accurate variant-calling evaluation. _Nat. Methods_ 15, 595–597 (2018). Article
Google Scholar * Jeffares, D. C. et al. Transient structural variations have strong effects on quantitative traits and reproductive isolation in fission yeast. _Nat. Commun._ 8, 14061
(2017). Article CAS Google Scholar * Simão, F. A., Waterhouse, R. M., Ioannidis, P., Kriventseva, E. V. & Zdobnov, E. M. BUSCO: assessing genome assembly and annotation completeness
with single-copy orthologs. _Bioinformatics._ 31, 3210–3212 (2015). Article Google Scholar * Zerbino, D. R. et al. Ensembl 2018. _Nucleic Acids Res._ 46, D754–D761 (2018). Article CAS
Google Scholar * Jain, C., Koren, S., Dilthey, A., Phillippy, A. M. & Aluru, S. A fast adaptive algorithm for computing whole-genome homology maps. _Bioinformatics._ 34, i748–i756
(2018). Article CAS Google Scholar Download references ACKNOWLEDGEMENTS We would like to thank J. Harting for assistance with HLA typing, K. Robertshaw for figure generation, J. Wilson
and J. Ziegle for providing PacBio CLR datasets and J. Puglisi for critical reading of the manuscript. S.K. and A.M.P. were supported by the Intramural Research Program of the National Human
Genome Research Institute, National Institutes of Health. This work utilized the computational resources of the NIH HPC Biowulf cluster (https://hpc.nih.gov). This work was supported by NIH
grant no. 1R01HG010040 to H.L. and NSFC grant nos. 31571353 and 31822029 to J.R. M.C.S. is funded by the National Science Foundation (grant no. DBI-1350041) and National Institutes of
Health (grant no. R01-HG006677). F.J.S. and M.M. are funded by NIH grant no. UM1 HG008898. T.M. acknowledges funding from the German Research Foundation (DFG) (grant nos. 391137747 and
395192176). N.D.O. and J.M.Z. were supported by intramural funding from the National Institute of Standards and Technology and an interagency agreement with the U.S. Food and Drug
Administration. This work utilized computational resources of DNAnexus and Google to apply DeepVariant to CCS reads. Certain commercial equipment, instruments or materials are identified to
specify adequate experimental conditions or reported results. Such identification does not imply recommendation or endorsement by the National Institute of Standards, nor does it imply that
the equipment, instruments or materials identified are necessarily the best available for the purpose. AUTHOR INFORMATION Author notes * These authors contributed equally: Aaron M. Wenger,
Paul Peluso. AUTHORS AND AFFILIATIONS * Pacific Biosciences, Menlo Park, CA, USA Aaron M. Wenger, Paul Peluso, William J. Rowell, Richard J. Hall, Gregory T. Concepcion, Armin Töpfer, Yufeng
Qian, David R. Rank & Michael W. Hunkapiller * Google Inc., Mountain View, CA, USA Pi-Chuan Chang, Alexey Kolesnikov, Mark A. DePristo & Andrew Carroll * Center for Bioinformatics,
Saarland University, Saarbrücken, Germany Jana Ebler & Tobias Marschall * Max Planck Institute for Informatics, Saarbrücken, Germany Jana Ebler & Tobias Marschall * Graduate School
of Computer Science, Saarland University, Saarbrücken, Germany Jana Ebler * DNAnexus, Mountain View, CA, USA Arkarachai Fungtammasan & Chen-Shan Chin * National Institute of Standards
and Technology, Gaithersburg, MD, USA Nathan D. Olson & Justin M. Zook * Department of Computer Science, Johns Hopkins University, Baltimore, MD, USA Michael Alonge & Michael C.
Schatz * Human Genome Sequencing Center, Baylor College of Medicine, Houston, TX, USA Medhat Mahmoud & Fritz J. Sedlazeck * Genome Informatics Section, Computational and Statistical
Genomics Branch, National Human Genome Research Institute, Bethesda, MD, USA Adam M. Phillippy & Sergey Koren * Max Planck Institute of Molecular Cell Biology and Genetics, Dresden,
Germany Gene Myers * Agricultural Genomics Institute, Chinese Academy of Agricultural Sciences, Shenzhen, China Jue Ruan * Dana-Farber Cancer Institute, Boston, MA, USA Heng Li Authors *
Aaron M. Wenger View author publications You can also search for this author inPubMed Google Scholar * Paul Peluso View author publications You can also search for this author inPubMed
Google Scholar * William J. Rowell View author publications You can also search for this author inPubMed Google Scholar * Pi-Chuan Chang View author publications You can also search for this
author inPubMed Google Scholar * Richard J. Hall View author publications You can also search for this author inPubMed Google Scholar * Gregory T. Concepcion View author publications You
can also search for this author inPubMed Google Scholar * Jana Ebler View author publications You can also search for this author inPubMed Google Scholar * Arkarachai Fungtammasan View
author publications You can also search for this author inPubMed Google Scholar * Alexey Kolesnikov View author publications You can also search for this author inPubMed Google Scholar *
Nathan D. Olson View author publications You can also search for this author inPubMed Google Scholar * Armin Töpfer View author publications You can also search for this author inPubMed
Google Scholar * Michael Alonge View author publications You can also search for this author inPubMed Google Scholar * Medhat Mahmoud View author publications You can also search for this
author inPubMed Google Scholar * Yufeng Qian View author publications You can also search for this author inPubMed Google Scholar * Chen-Shan Chin View author publications You can also
search for this author inPubMed Google Scholar * Adam M. Phillippy View author publications You can also search for this author inPubMed Google Scholar * Michael C. Schatz View author
publications You can also search for this author inPubMed Google Scholar * Gene Myers View author publications You can also search for this author inPubMed Google Scholar * Mark A. DePristo
View author publications You can also search for this author inPubMed Google Scholar * Jue Ruan View author publications You can also search for this author inPubMed Google Scholar * Tobias
Marschall View author publications You can also search for this author inPubMed Google Scholar * Fritz J. Sedlazeck View author publications You can also search for this author inPubMed
Google Scholar * Justin M. Zook View author publications You can also search for this author inPubMed Google Scholar * Heng Li View author publications You can also search for this author
inPubMed Google Scholar * Sergey Koren View author publications You can also search for this author inPubMed Google Scholar * Andrew Carroll View author publications You can also search for
this author inPubMed Google Scholar * David R. Rank View author publications You can also search for this author inPubMed Google Scholar * Michael W. Hunkapiller View author publications You
can also search for this author inPubMed Google Scholar CONTRIBUTIONS A.M.W., D.R.R., M.W.H. and P.P. designed the study. D.R.R. and P.P. developed the sample preparation protocol and
performed sample preparation. D.R.R., P.P. and Y.Q. performed sequencing. A.C., A.K., C-S.C., M.A.D. and P.C. adapted the algorithms and implementation of DeepVariant. A.C., A.F., A.K.,
A.M.P., A.M.W., A.T., C-S.C., D.R.R., F.J.S., G.M., G.T.C., H.L., J.E., J.M.Z., J.R., M.A., M.A.D., M.C.S., M.M., N.D.O., P.C., P.P., R.J.H., S.K., T.M. and W.J.R. performed analysis. A.C.,
A.M.P., C-S.C., D.R.R., F.J.S., J.M.Z., M.A.D., M.C.S. and M.W.H. supervised analysis. A.C., A.M.W., D.R.R., G.M., J.M.Z., P.P., R.J.H., S.K. and W.J.R. wrote the manuscript. See
Supplementary Note for more detailed author contributions. All authors reviewed and approved the final manuscript. CORRESPONDING AUTHORS Correspondence to David R. Rank or Michael W.
Hunkapiller. ETHICS DECLARATIONS COMPETING INTERESTS A.M.W., A.T., D.R.R., G.T.C., M.W.H., P.P., R.J.H., W.J.R. and Y.Q. are employees and shareholders of Pacific Biosciences. A.C., A.K.,
M.A.D. and P.C. are employees and shareholders of Google. A.F. and C-S.C. are employees and shareholders of DNAnexus. A.C. is a shareholder and was an employee of DNAnexus for a portion of
this work. ADDITIONAL INFORMATION PUBLISHER’S NOTE: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations. INTEGRATED
SUPPLEMENTARY INFORMATION SUPPLEMENTARY FIGURE 1 CCS PROTOCOL DEVELOPMENT. (A) Distribution of polymerase read lengths for a 10 kb _E.coli_ amplicon library and 30 kb _E. coli_ whole genome
library sequenced for 10 hours with identical conditions. (B) Distribution of polymerase read lengths for an 8 kb fragment from a BsaAI-digested lambda library sequenced for 4 hours with (5
hour) and without (0 hour) pre-extension to reduce “early-terminating” reads and select surviving polymerase-template complexes. (C) Sample preparation and sequencing workflow. (D)
BioAnalyzer trace for the SMRTbell library, sheared to target 15–20 kb fragments. “FU” is fluorescence units. (E) BioAnalyzer trace for ELF fractions of the SMRTbell library. (f) The
fraction centered around 15 kb was used for sequencing. SUPPLEMENTARY FIGURE 2 CCS READ ACCURACY AND COVERAGE UNIFORMITY. (A) Distribution of accuracy predicted by the CCS algorithm for
reads with fewer than 3 passes and at least 3 passes, which we consider a minimum pass count for CCS. Approximately half of reads have 3 or more passes; among those nearly all achieve Q20
predicted accuracy. (B) Distributions of HG002 concordance, measured against the GIAB benchmark, at levels of predicted read accuracy (R2 of median = 0.9980). Orange lines are medians; boxes
extend from lower to upper quartiles; whiskers extend 1.5 interquartile distances; n=1,000 reads at each predicted accuracy. (C) Distribution of difference between concordance and predicted
read accuracy shows that the prediction is well-calibrated to the empirical concordance. (D) Distribution of coverage in 500 bp windows at non-gap positions in GRCh37. (E) Coverage
distributions at levels of [GC] content, measured in 500 bp windows. Orange lines are medians; boxes extend from lower to upper quartiles; whiskers extend 1.5 interquartile distances; n per
distribution is listed above the plot. SUPPLEMENTARY FIGURE 3 CCS READ PILEUPS AT HLA GENES. The 13.5 kb CCS reads provide phasing and full four-field resolution of HLA class I and II genes
(Methods Mol. Biol. 1802, 135–153, 2018), including (A) _HLA-A_ for which HG002 has alleles that differ in the first field, and (B) _HLA-DPA1_ for which HG002 has alleles that differ only in
the fourth field from two intronic single nucleotide polymorphisms across 20 kb. SUPPLEMENTARY FIGURE 4 THEORETICAL PHASE BLOCK N50 IN HG002 AT DIFFERENT READ LENGTHS. To model the phase
blocks achievable with a given read length, cuts were introduced between heterozygous variants in the GIAB trio-phased HG002 variant callset that are separated by more than the read length,
which effectively assumes that adjacent heterozygous variants separated by less than the read length can be phased. SUPPLEMENTARY FIGURE 5 STRUCTURAL VARIANT CALLING PERFORMANCE. Precision,
recall, and number of variant calls in the GIAB benchmark regions for the PacBio CCS mapping-based variant callers (A) pbsv and (B) Sniffles; the PacBio CCS assembly-based callers (C)
paftools/Canu (polished) and (D) paftools/FALCON (unpolished); the PacBio CLR mapping-based callers (E) pbsv and (F) Sniffles; the Illumina short-read callers (G) Manta and (H) Delly; and
the 10X Genomics callers (I) LongRanger and (J) paftools/Supernova. Negative length indicates a deletion; positive length indicates an insertion. The histogram bin size is 50 bp for variants
shorter than 1 kb, and 500 bp for variants >1 kb. Precision and recall are measured with Truvari against the GIAB benchmark. SUPPLEMENTARY FIGURE 6 HAPLOTYPE RESOLUTION IN THE CANU MIXED
ASSEMBLY. The Canu mixed assembly is larger than the haploid human genome size because it resolves some heterozygous loci into separate maternal and paternal haplotypes. (A, B) Loci where
the long primary contig matches the paternal haplotype and a smaller contig matches the maternal haplotype. (C, D) Similar loci where the long primary contig matches the maternal haplotype
and a smaller contig matches the paternal haplotype. SUPPLEMENTARY FIGURE 7 MIS-PHASING ANALYSIS OF PARENTAL ASSEMBLIES. Parent-specific heterozygous SNVs were identified in the GIAB
benchmark callset. The “Mis-phased SNVs fraction” is the fraction of parent-specific SNVs from the wrong parent (e.g. [SNVpat]/[SNVpat+SNVmat] in a maternal contig). No large contigs have a
high mis-phased SNVs ratio, which suggests proper phasing of the (A) Canu paternal, (B) Canu maternal, (C) FALCON paternal, and (D) FALCON maternal assemblies. SUPPLEMENTARY FIGURE 8
COVERAGE TITRATION FOR VARIANT CALLING, PHASING, AND ASSEMBLY. Precision and recall for (A) SNVs and (B) indels called with DeepVariant (CCS), subsampling in steps of 3%. (C) Precision and
recall for structural variants called with pbsv, subsampling in steps of 10%. (D) Phase block N50 for phasing of the 28-fold DeepVariant (CCS) callset with WhatsHap, subsampling in steps of
10%. Phasing performance is similar with a callset produced at matched coverage (not shown). _De novo_ assembly (E) completeness measured as total assembly size, (F) contiguity measured as
contig N50, and (G) correctness measured as concordance to the HG002 GIAB benchmark for wtdbg2 assembly, subsampling reads in steps of 10%. SUPPLEMENTARY FIGURE 9 LIKELY ERRORS IN THE GIAB
BENCHMARK IDENTIFIED BY CCS CALLSETS. Manual curation of discrepancies between the GIAB benchmark and CCS variant callsets identifies benchmark errors for all variant types that are
correctable using the CCS variant callsets. Shown are four loci that the GIAB benchmark records as homozygous reference where CCS reads identify likely heterozygous variation: (A) Three SNVs
supported by CCS reads and 6 kb matepair reads. (B) A 2 bp insertion supported by CCS reads, 10X Genomics reads, and 6 kb matepair reads. (C) A 328 bp insertion supported by CCS reads and
assemblies. (D) An 83 bp deletion supported by CCS reads. SUPPLEMENTARY INFORMATION SUPPLEMENTARY INFORMATION Supplementary Figs. 1–9, Supplementary Tables 1–12 and Supplementary Note.
REPORTING SUMMARY RIGHTS AND PERMISSIONS Reprints and permissions ABOUT THIS ARTICLE CITE THIS ARTICLE Wenger, A.M., Peluso, P., Rowell, W.J. _et al._ Accurate circular consensus long-read
sequencing improves variant detection and assembly of a human genome. _Nat Biotechnol_ 37, 1155–1162 (2019). https://doi.org/10.1038/s41587-019-0217-9 Download citation * Received: 23
January 2019 * Accepted: 08 July 2019 * Published: 12 August 2019 * Issue Date: October 2019 * DOI: https://doi.org/10.1038/s41587-019-0217-9 SHARE THIS ARTICLE Anyone you share the
following link with will be able to read this content: Get shareable link Sorry, a shareable link is not currently available for this article. Copy to clipboard Provided by the Springer
Nature SharedIt content-sharing initiative