- Select a language for the TTS:
- UK English Female
- UK English Male
- US English Female
- US English Male
- Australian Female
- Australian Male
- Language selected: (auto detect) - EN
Play all audios:
ABSTRACT Characterizing multipartite quantum systems is crucial for quantum computing and many-body physics. The problem, however, becomes challenging when the system size is large and the
properties of interest involve correlations among a large number of particles. Here we introduce a neural network model that can predict various quantum properties of many-body quantum
states with constant correlation length, using only measurement data from a small number of neighboring sites. The model is based on the technique of multi-task learning, which we show to
offer several advantages over traditional single-task approaches. Through numerical experiments, we show that multi-task learning can be applied to sufficiently regular states to predict
global properties, like string order parameters, from the observation of short-range correlations, and to distinguish between quantum phases that cannot be distinguished by single-task
networks. Remarkably, our model appears to be able to transfer information learnt from lower dimensional quantum systems to higher dimensional ones, and to make accurate predictions for
Hamiltonians that were not seen in the training. SIMILAR CONTENT BEING VIEWED BY OTHERS STOCHASTIC REPRESENTATION OF MANY-BODY QUANTUM STATES Article Open access 16 June 2023 EMPOWERING DEEP
NEURAL QUANTUM STATES THROUGH EFFICIENT OPTIMIZATION Article Open access 01 July 2024 DIRECT ENTANGLEMENT DETECTION OF QUANTUM SYSTEMS USING MACHINE LEARNING Article Open access 20 February
2025 INTRODUCTION The experimental characterization of many-body quantum states is an essential task in quantum information and computation. Neural networks provide a powerful approach to
quantum state characterization1,2,3,4, enabling a compact representation of sufficiently structured quantum states5. In recent years, different types of neural networks have been
successfully utilized to predict properties of quantum systems, including quantum fidelity6,7,8 and other measures of similarity9,10, quantum entanglement11,12,13, entanglement
entropy1,14,15, two-point correlations1,2,14 and Pauli expectation values4,16, as well as to identify phases of matter17,18,19,20,21. A challenge in characterizing multiparticle quantum
systems is that the number of measurement settings rapidly increases with the system size. Randomized measurement techniques22,23,24,25,26,27,28,29,30 provide an effective way to predict the
properties of generic quantum states by using a reduced number of measurement settings, randomly sampled from the set of products of single particle observables. In the special case of
many-body quantum systems subject to local interactions, however, sampling from an even smaller set of measurements may be possible, due to the additional structure of the states under
consideration, which may enable a characterization of the state based only on short-range correlations, that is, correlations involving only a small number of neighboring sites. The use of
short-range correlations has been investigated for the purpose of quantum state tomography31,32,33,34,35 and entanglement detection36,37. A promising approach is to employ neural networks to
predict global quantum properties directly from data obtained by sampling over a set of short-range correlations. In this paper, we develop a neural network model for predicting various
properties of quantum many-body states from short-range correlations. Our model utilizes the technique of multi-task learning38 to generate concise state representations that integrate
diverse types of information. In particular, the model can integrate information obtained from few-body measurements into a representation of the overall quantum state, in a way that is
reminiscent of the quantum marginal problem39,40,41. The state representations produced by our model are then used to learn new physical properties that were not seen during the training,
including global properties such as string order parameters and many-body topological invariants42. For ground states with short-range correlations, we find that our model accurately
predicts nonlocal features using only measurements on a few nearby particles. With respect to traditional, single-task neural networks, our model achieves more precise predictions with
comparable amounts of input data and enables a direct, unsupervised classification of symmetry-protected topological (SPT) phases that could not be distinguished in the single-task approach.
In addition, we find that, after the training is completed, the model can be applied to quantum states and Hamiltonians outside the original training set, and even to quantum systems of
higher dimension. This strong performance on out-of-distribution states suggests that the multi-task approach is a promising tool for exploring the next frontier of intermediate-scale
quantum systems. RESULTS MULTI-TASK FRAMEWORK FOR QUANTUM PROPERTIES Consider the scenario where an experimenter has access to multiple copies of an unknown quantum state _ρ__θ_,
characterized by some physical parameters _θ_. For example, _ρ__θ_ could be a ground state of many-body local Hamiltonian depending on _θ_. The experimenter’s goal is to predict a set of
properties of the quantum state, such as the expectation values of some observables, or some nonlinear functions, such as the von Neumann entropy. The experimenter is able to perform a
restricted set of quantum measurements, denoted by \({{\mathcal{M}}}\). Each measurement \({{\bf{M}}}\in {{\mathcal{M}}}\) is described by a positive operator-valued measure (POVM) M =
(_M__j_), where the index _j_ labels the measurement outcome, each _M__j_ is a positive operator acting on the system’s Hilbert space, and the normalization condition ∑_j__M__j_ = _I_ is
satisfied. In general, the measurement set \({{\mathcal{M}}}\) may not be informationally complete. For multipartite systems, we will typically take \({{\mathcal{M}}}\) to consist of
short-range measurements, that is, local measurements performed on a small number of neighboring systems, although this choice is not a necessary part of our multi-task learning framework.
It is also worth noting that choosing short-range measurements for the set \({{\mathcal{M}}}\) does not necessarily mean that the experimenter has to physically isolate a subset of
neighboring systems before doing their measurements. The access to short-range measurement statistics can obtained, _e.g_. from product measurements performed jointly on all systems, by
discarding the outcomes generated from systems outside the subset of interest. In this way, a single product measurement performed jointly on all systems can provide data to multiple
short-range measurements. To collect data, the experimenter randomly picks a subset of measurements \({{\mathcal{S}}}\subset {{\mathcal{M}}}\), and performs them on different copies of the
state _ρ__θ_. We will denote by _s_ the number of measurements in \({{\mathcal{S}}}\), and by \({{{\bf{M}}}}_{i}:\!\!=\left({M}_{ij}\right)\) the _i_-th POVM in \({{\mathcal{S}}}\). For
simplicity, if not specified otherwise, we assume that each measurement in \({{\mathcal{S}}}\) is repeated sufficiently many times, so that the experimenter can reliably estimate the outcome
distribution \({{{\bf{d}}}}_{i}:\!\!=({d}_{ij})\), where \({d}_{ij}:\!\!={{\rm{tr}}}(\rho {M}_{ij})\). The experimenter’s goal is to predict multiple quantum properties of _ρ__θ_ using the
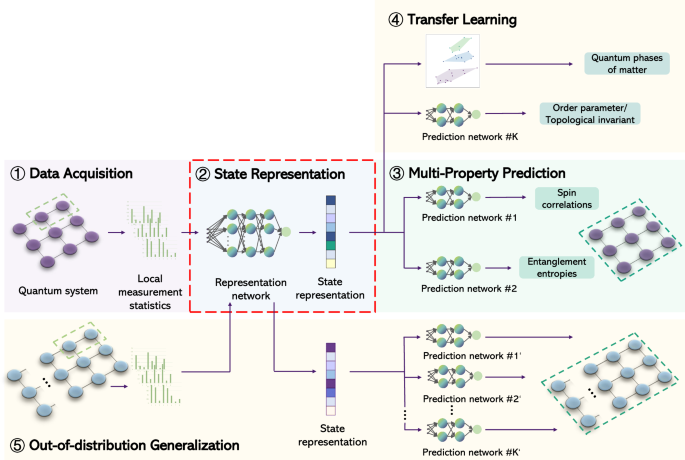
outcome distributions \({({{{\bf{d}}}}_{i})}_{i=1}^{s}\). This task is achieved by a neural network that consists of an encoder and multiple decoders, where the encoder \({{\mathcal{E}}}\)
produces a representation of quantum states and the _k_-th decoder \({{{\mathcal{D}}}}_{k}\) produces a prediction of the _k_-th property of interest. Due to their roles, the encoder and
decoders are also known as representation and prediction networks, respectively. The input of the representation network \({{\mathcal{E}}}\) is the outcome distribution D_i_, together with a
parametrization of the corresponding measurement M_i_, hereafter denoted by M_i_. From the pair of data (D_i_, M_i_), the network produces a state representation
\({{{\bf{r}}}}_{i}:\!\!={{\mathcal{E}}}({{{\bf{d}}}}_{i},{{{\bf{m}}}}_{i})\). To combine the state representations arising from different measurements in \({{\mathcal{S}}}\), the network
computes the average \({{\bf{r}}}:\!\!=\frac{1}{s}{\sum }_{i=1}^{s}{{{\bf{r}}}}_{i}\). At this point, the vector R can be viewed as a representation of the unknown quantum state _ρ_. Each
prediction network \({{{\mathcal{D}}}}_{k}\) is dedicated to a different property of the quantum state. In the case of multipartite quantum systems, we include the option of evaluating the
property on a subsystem, specified by a parameter _q_. We denote by _f__k_,_q_(_ρ__θ_) the correct value of the _k_-th property of subsystem _q_ when the total system is in the state _ρ__θ_.
Upon receiving the state representation R and the subsystem specification _q_, the prediction network produces an estimate \({{{\mathcal{D}}}}_{k}({{\bf{r}}},q)\) of the value
_f__k_,_q_(_ρ_). The representation network and all the prediction networks are trained jointly, with the goal of minimizing the total prediction error on a set of fiducial states. The
fiducial states are chosen by randomly sampling a set of physical parameters \({({\theta }_{l})}_{l=1}^{L}\). For each fiducial state \({\rho }_{{\theta }_{{{\bf{l}}}}}\), we independently
sample a set of measurements \({{{\mathcal{S}}}}_{l}\) and calculate the outcome distributions for each measurement in the set \({{{\mathcal{S}}}}_{l}\). We randomly choose a subset of
properties \({{{\mathcal{K}}}}_{l}\) for each \({\rho }_{{\theta }_{{{\bf{l}}}}}\), where each property \(k\in {{{\mathcal{K}}}}_{l}\) corresponds to a set of subsystems
\({{{\mathcal{Q}}}}_{k}\), and then calculate the correct values of the quantum properties \(\{{f}_{k,q}({\rho }_{{\theta }_{l}})\}\) for all properties \(k\in {{{\mathcal{K}}}}_{l}\)
associated with subsystems \(q\in {{{\mathcal{Q}}}}_{k}\). The training data may be either classically simulated or gathered by actual measurements on the set of fiducial states, or it could
also be obtained by any combination of these two approaches. During the training, we do not provide the model with any information about the physical parameters _θ__l_ or about the
functions _f__k_,_q_. Instead, the internal parameters of the neural networks are jointly optimized in order to minimize the prediction errors \(| {{{\mathcal{D}}}}_{k}\left(1/s\mathop{\sum
}_{i=1}^{s}{{\mathcal{E}}}(\{{{{\bf{d}}}}_{i},\,{{{\bf{m}}}}_{i}\}),q\right)-{f}_{k,q}({\rho }_{\theta })| \) summed over all the fiducial states, all chosen properties, and all chosen
subsystems. After the training is concluded, our model can be used for predicting quantum properties, either within the set of properties seen during training or outside this set. The
requested properties are predicted on a new, unknown state _ρ__θ_, and even out-of-distribution state _ρ_ that has a structural similarity with the states in the original distribution, e.g.,
a ground state of the same type of Hamiltonian, but for a quantum system with a larger number of particles. The high-level structure of our model is illustrated in Fig. 1, while the details
of the neural networks are presented in Methods. LEARNING GROUND STATES OF CLUSTER-ISING MODEL We first test the performance of our model on a relatively small system of _N_ = 9 qubits
whose properties can be explicitly calculated. For the state family, we take the ground states of one-dimensional cluster-Ising model43 $${H}_{{{\rm{cI}}}}=-\mathop{\sum }_{i=1}^{N-2}{\sigma
}_{i}^{z}{\sigma }_{i+1}^{x}{\sigma }_{i+2}^{z}-{h}_{1}{\sum }_{i=1}^{N}{\sigma }_{i}^{x}-{h}_{2}{\sum }_{i=1}^{N-1}{\sigma }_{i}^{x}{\sigma }_{i+1}^{x}.$$ (1) The ground state falls in one
of three phases, depending on the values of the parameters (_h_1, _h_2). The three phases are: the SPT phase, the paramagnetic phase, and the antiferromagnetic phase. SPT phase can be
distinguished from two other phases by measuring the string order parameter44,45\(\langle \tilde{S}\rangle :\!\!=\langle {\sigma }_{1}^{z}{\sigma }_{2}^{x}{\sigma }_{4}^{x}\ldots {\sigma
}_{N-3}^{x}{\sigma }_{N-1}^{x}{\sigma }_{N}^{z}\rangle \), which is a global property involving (_N_ + 3)/2 qubits. We test our network model on the ground states corresponding to a 64 × 64
square grid in the parameter region (_h_1, _h_2) ∈ [0, 1.6] × [ − 1.6, 1.6]. For the set of accessible measurements \({{\mathcal{M}}}\), we take all possible three-nearest-neighbor Pauli
measurements, corresponding to the observables \({\sigma }_{i}^{\alpha }{\sigma }_{i+1}^{\beta }{\sigma }_{i+2}^{\gamma }\), where _i_ ∈ {1, 2, … , _N_ − 2} and _α_, _β_, _γ_ ∈ {_x_, _y_,
_z_}. It is worth noting that, when two measurements \({{\bf{M}}}\,\ne\, {{{\bf{M}}}}^{{\prime} }\) act on disjoint qubit triplets or coincide at overlapping qubits, these measurements can
be performed simultaneously on a single copy of the state, thereby reducing the number of data collection rounds. In general, increasing the range of the correlations among Pauli
measurements can increase the performance of the network. For example, using the correlations from Pauli measurements on triplets of neighboring qubits (as described above) leads to a better
performance than using correlations from Pauli measurements on pairs of neighboring qubits, as illustrated in Supplementary Note 5. On the other hand, increasing the range of the
correlations also increases the size of the input to the neural network, making the training more computationally expensive. For the prediction tasks, we consider two properties: (A1) the
two-point correlation function \({{{\mathcal{C}}}}_{1j}^{\alpha }:\!\!={\langle {\sigma }_{1}^{\alpha }{\sigma }_{j}^{\alpha }\rangle }_{\rho }\), where 1 < _j_ ≤ _N_ and _α_ = _x_, _z_;
(A2) the Rényi entanglement entropy of order two \({S}_{A}:\!\!=-{\log }_{2}\left({{\rm{tr}}}{\rho }_{A}^{2}\right)\) for subsystem _A_ = [1, 2, … , _i_], where 1 ≤ _i_ < _N_. Both
properties (A1) and (A2) can be either numerically evaluated, or experimentally estimated by preparing the appropriate quantum state and performing randomized measurements27. We train our
neural network with respect to the fiducial ground states corresponding to 300 randomly chosen points from our 4096-element grid. For each fiducial state, we provide the neural network with
the outcome distributions of _s_ = 50 measurements, randomly chosen from the 243 measurements in \({{\mathcal{M}}}\). Half of these fiducial states randomly chosen from the whole set are
labeled by the values of property (A1) and the other half are labeled by property (A2). After training is concluded, we apply our trained model to predicting properties (A1)-(A2) for all
remaining ground states corresponding to points on the grid. For each test state, the representation network is provided with the outcome distributions on _s_ = 50 measurement settings
randomly chosen from \({{\mathcal{M}}}\). Figure 2a illustrates the coefficient of determination (_R_2), averaged over all test states, for each type of property. Notably, all the values of
_R_2 observed in our experiments are above 0.95. Our network makes accurate predictions even near the boundary between the SPT phase and paramagnetic phase, in spite of the fact that phase
transitions typically make it more difficult to capture the ground state properties from limited measurement data. For a ground state close to the boundary, marked by a star in the phase
diagram (Fig. 3d), the predictions of the entanglement entropy \({{{\mathcal{S}}}}_{A}\) and spin correlation \({{{\mathcal{C}}}}_{1j}^{z}\) are close to the corresponding ground truths, as
shown in Fig. 2d and e, respectively. In general, the accuracy of the predictions depends on the number of samplings for each measurement as well as the number of measurement settings. For
our experiments, the dependence is illustrated in Fig. 2b and c. To examine whether our multi-task neural network model enhances the prediction accuracy compared to single-task networks, we
perform ablation experiments46. We train three individual single-task neural networks as our baseline models, each of which predicts spin correlations in Pauli-x axis, spin correlations in
Pauli-z axis, and entanglement entropies, respectively. For each single-task neural network, the training provides the network with the corresponding properties for the 300 fiducial ground
states, without providing any information about the other properties. After the training is concluded, we apply each single-task neural network to predict the corresponding properties on all
the test states and use their predictions as baselines to benchmark the performance of our multi-task neural network. Figure 2a compares the values of _R_2 for the predictions of our
multi-task neural model with those of the single-task counterparts. The results demonstrate that learning multiple physical properties simultaneously enhances the prediction of each
individual property. TRANSFER LEARNING TO NEW TASKS We now show that the state representations produced by the encoder can be used to perform new tasks that were not encountered during the
training phase. In particular, we show that state representations can be used to distinguish between the phases of matter associated to different values of the Hamiltonian parameters in an
unsupervised manner. To this purpose, we project the representations of all the test states onto a two-dimensional (2D) plane using the t-distributed stochastic neighbor embedding (t-SNE)
algorithm. The results are shown in Fig. 3a. Every data point shows the exact value of the string order parameter, which distinguishes between the SPT phase and the other two phases. Quite
strikingly, we find that the disposition of the points in the 2D representation matches the values of the string order parameter, even though no information about the string order parameters
was provided during the training, and even though the string order is a global property, while the measurement data provided to the network came from a small number of neighboring sites. A
natural question is whether the accurate classification of phases of matter observed above is a consequence of the multi-task nature of our model. To shed light into this question, we
compare the results of our multi-task network with those of single-task neural networks, feeding the state representations generated by these networks into the t-SNE algorithm to produce a
2D representation. The pattern of the projected state representations in Fig. 3b indicates that when trained only with the values of entanglement entropies, the neural network cannot
distinguish between the paramagnetic phase and the antiferromagnetic phase. Interestingly, a single-task network trained only on the spin correlations can still distinguish the SPT phase
from the other two phases, as shown in Fig. 3c. However, in the next section we see that applying random local gates induces errors in the single-task network, while the multi-task network
still achieves a correct classification of the different phases. Quantitatively, the values of the string order parameter can be extracted from the state representations using another neural
network \({{\mathcal{N}}}\). To train this network, we randomly pick 100 reference states {_σ__i_} out of the 300 fiducial states and minimize the error \({\sum }_{i=1}^{100}|
{{\mathcal{N}}}({{{\bf{r}}}}_{{\sigma }_{i}})-{\langle \tilde{S}\rangle }_{{\sigma }_{i}}| \). Then, we use the trained neural network \({{\mathcal{N}}}\) to produce the prediction
\({{\mathcal{N}}}({{{\bf{r}}}}_{\rho })\) of \({\langle \tilde{S}\rangle }_{\rho }\) for every other state _ρ_. The prediction for each ground state is shown in the phase diagram (Fig. 3d),
where the 100 reference states are marked by white circles. The predictions are close to the true values of string order parameters, with the coefficient of determination between the
predictions and the ground truth being 0.97. It is important to stress that, while the network \({{\mathcal{N}}}\) was trained on values of the string order parameter, the representation
network \({{\mathcal{E}}}\) was not provided any information about this parameter. Note also that the values of the Hamiltonian parameters (_h_1, _h_2) are just provided in the figure for
the purpose of visualization: in fact, no information about the Hamiltonian parameters was provided to the network during training or test. In Supplementary Note 5, we show that our neural
network model trained for predicting entanglement entropy and spin correlations can also be transferred to other ground-state properties of the cluster-Ising model. GENERALIZATION TO
OUT-OF-DISTRIBUTION STATES In the previous sections, we assumed that both the training and the testing states were randomly sampled from a set of ground states of the cluster-Ising model
(1). In this subsection, we explore how a model trained on a given set of quantum states can generalize to states outside the original set in an unsupervised or weakly supervised manner. Our
first finding is that our model, trained on the ground states of the cluster-Ising model, can effectively cluster general quantum states in the SPT phase and the trivial phase (respecting
the symmetry of bit flips at even/odd sites), without further training. Random quantum states in SPT (trivial) phase can be prepared by applying short-range symmetry-respecting local random
quantum gates on a cluster state in the SPT phase (a product state \({\left\vert+\right\rangle }^{\otimes N}\) in the paramagnetic phase). For these random quantum states, we follow the same
measurement strategy adopted before, feed the measurement data into our trained representation network, and use t-SNE to project the state representations onto a 2D plane. When the quantum
circuit consists of a layer of translation-invariant next-nearest neighbor symmetry-respecting random gates, our model successfully classifies the output states into their respective SPT
phase and trivial phase in both cases, as shown by Fig. 4a. In contrast, feeding the same measurement data into the representation network trained only on spin correlations fails to produce
two distinct clusters via t-SNE, as shown by Fig. 4b. While this neural network successfully classifies different phases for the cluster-Ising model, random local quantum gates confuse it.
This failure is consistent with the recent observation that extracting linear functions of a quantum state is insufficient for classifying arbitrary states within SPT phase and trivial
phase26. We then prepare more complex states by applying two layers of translation-invariant random gates consisting of both nearest neighbor and next-nearest neighbor gates preserving the
symmetry onto the initial states. The results in Fig. 4c show that the state representations of these two phases remain different, but the boundary between them in the representation space
is less clearly identified. Whereas, the neural network trained only on spin correlations fails to classify these two phases, as shown by Fig. 4d. Finally, we demonstrate that our neural
model, trained on the cluster-Ising model, can adapt to learn the ground states of a new, perturbed Hamiltonian47 $${H}_{{{\rm{pcI}}}}={H}_{{{\rm{cI}}}}+{h}_{3}\mathop{\sum
}_{i=1}^{N-1}{\sigma }_{i}^{z}{\sigma }_{i+1}^{z}.$$ (2) This perturbation breaks the original symmetry, shifts the boundary of the cluster phase, and introduces a new phase of matter. In
spite of these substantial changes, Fig. 5a shows that our model, trained on the unperturbed cluster-Ising model, successfully identifies the different phases, including the new phase from
the perturbation. Moreover, using just 10 randomly chosen additional reference states (marked by white circles in Fig. 5b), the original prediction network can be adjusted to predict the
values of \(\langle \tilde{{{\mathcal{S}}}}\rangle \) from state representations. As shown in Fig. 5b, the predicted values closely match the ground truths in Fig. 5c, achieving a
coefficient of determination of up to 0.956 between the predictions and the ground truths. LEARNING GROUND STATES OF XXZ MODEL We now apply our model to a larger quantum system, consisting
of 50 qubits in ground states of the bond-alternating XXZ model24 $$H=\, J{\sum }_{i=1}^{N/2}\left({\sigma }_{2i-1}^{x}{\sigma }_{2i}^{x}+{\sigma }_{2i-1}^{y}{\sigma }_{2i}^{y}+\delta
{\sigma }_{2i-1}^{z}{\sigma }_{2i}^{z}\right)\\ +\,{J}^{{\prime} }{\sum }_{i=1}^{N/2-1}\left({\sigma }_{2i}^{x}{\sigma }_{2i+1}^{x}+{\sigma }_{2i}^{y}{\sigma }_{2i+1}^{y}+\delta {\sigma
}_{2i}^{z}{\sigma }_{2i+1}^{z}\right),$$ (3) where _J_ and \({J}^{{\prime} }\) are the alternating values of the nearest-neighbor spin couplings. We consider a set of ground states
corresponding to a 21 × 21 square grid in the parameter region \((J/{J}^{{\prime} },\delta )\in (0,\,3)\times (0,\,4)\). Depending on the ratio of \(J/{J}^{{\prime} }\) and the strength of
_δ_, the corresponding ground state falls into one of three possible phases: trivial SPT phase, topological SPT phase, and symmetry broken phase. Unlike the SPT phases of cluster-Ising
model, the SPT phases of bond-alternating XXZ model cannot be detected by any string order parameter. Both SPT phases are protected by bond-center inversion symmetry, and detecting them
requires a many-body topological invariant, called the partial reflection topological invariant24 and denoted by $${{{\mathcal{Z}}}}_{{{\rm{R}}}}:\!\!=\frac{{{\rm{tr}}}({\rho
}_{I}{{{\mathcal{R}}}}_{I})}{\sqrt{\left[{{\rm{tr}}}\left({\rho }_{{I}_{1}}^{2}\right)+{{\rm{tr}}}\left({\rho }_{{I}_{2}}^{2}\right)\right]/2}}.$$ (4) Here, \({{{\mathcal{R}}}}_{I}\) is the
swap operation on subsystem _I_ := _I_1 ∪ _I_2 with respect to the center of the spin chain, and _I_1 = [_N_/2 − 5, _N_/2 − 4, … , _N_/2] and _I_2 = [_N_/2 + 1, _N_/2 + 2, … , _N_/2 + 6] are
two subsystems with six qubits. For the set of possible measurements \({{\mathcal{M}}}\), we take all possible three-nearest-neighbor Pauli projective measurements, as we did earlier in the
cluster-Ising model. For the prediction tasks, we consider two types of quantum properties: (B1) nearest-neighbor spin correlations \({{{\mathcal{C}}}}_{i,i+1}^{\beta }:\!\!=\langle {\sigma
}_{i}^{\beta }{\sigma }_{i+1}^{\beta }\rangle (1\le i\le N-1)\), where _β_ = _x_, _z_; (B2) order-two Rényi mutual information _I__A_:_B_, where _A_ and _B_ are both 4-qubit subsystems:
either _A_1 = [22: 25], _B_1 = [26: 29] or _A_2 = [21: 24], _B_2 = [25: 28]. We train our neural network with respect to the fiducial ground states corresponding to 80 pairs of
\((J/{J}^{{\prime} },\delta )\), randomly sampled from the 441-element grid. For each fiducial state, we provide the neural network with the probability distributions corresponding to _s_ =
200 measurements randomly chosen from the 1350 measurements in \({{\mathcal{M}}}\). Half of the fiducial states randomly chosen from the entire set are labeled by the property of (B1), while
the other half are labeled by the property of (B2). After the training is concluded, we use our trained model to predict both properties (B1) and (B2) for all the ground states in the grid.
Figure 6a demonstrates the strong predictive performance of our model, where the values of _R_2 are above 0.92 for all properties averaged over test states. We benchmark the performances of
our multi-task neural network with the predictions of single-task counterparts. Here each single-task neural network, the size of which is same as the multi-task network, aims at predicting
one single physical property and is trained using the same set of measurement data of 80 fiducial states together with one of their properties: \({C}_{i,i+1}^{x}\), \({C}_{i,i+1}^{z}\),
\({I}_{{A}_{1}:{B}_{1}}\) and \({I}_{{A}_{2}:{B}_{2}}\). Figure 6a compares the coefficients of determination for the predictions of both our multi-task neural network and the single-task
neural networks, where each experiment is repeated multiple times over different sets of _s_ = 200 measurements randomly chosen from \({{\mathcal{M}}}\). The results indicate that our
multi-task neural model not only achieves higher accuracy in the predictions of all properties, but also is much more robust to different choices of quantum measurements. As in the case of
the cluster-Ising model, we also study how the number of quantum measurements _s_ and the number of samplings for each quantum measurement affect the prediction accuracy of our neural
network model, as shown by Fig. 6b and c. Additionally, in Supplementary Note 6 we test how the size of the quantum system affects the prediction accuracy given the same amount of local
measurement data, and how the number of layers in the representation network affects the prediction accuracy. Interestingly, we observe that reducing the number of layers from four to two
results in a significant decline in performance when predicting properties (B1) and (B2). This observation indicates that the depth of the network plays an important role in achieving
effective multi-task learning of the bond-alternating XXZ ground states. We show that, even in the larger-scale example considered in this section, the state representations obtained through
multi-task training contain information about the quantum phases of matter. In Fig. 7a, we show the 2D-projection of the state representations. The data points corresponding to ground
states in the topological SPT phase, the trivial SPT phase and the symmetry broken phase appear to be clearly separated into three clusters, while the latter two connected by a few data
points corresponding to ground states across the phase boundary. A few points, corresponding to ground states near phase boundaries of the topological SPT phase, are incorrectly clustered by
the t-SNE algorithm. The origin of the problem is that the correlation length of ground states near phase boundary becomes longer, and therefore the measurement statistics on
nearest-neighbor-three qubit subsystems cannot capture sufficient information for predicting the correct phase of matter. We further examine if the single-task neural networks above can
correctly classify the three different phases of matter. We project the state representations produced by each single-task neural network onto 2D planes by the t-SNE algorithm, as shown by
Fig. 7b and c. The pattern of projected representations in Fig. 7b implies that when trained only with the values of spin correlations, the neural network cannot distinguish the topological
SPT phase from the trivial SPT phase. The pattern in Fig. 7c indicates that when trained solely with mutual information, the performance of clustering is slightly improved, but still cannot
explicitly classify these two SPT phases. We also project the state representations produced by the neural network for predicting measurement outcome statistics3 onto a 2D plane. The
resulting pattern, shown in Fig. 7d, shows that the topological SPT phase and the trivial SPT phase cannot be correctly classified either. These observations indicate that a multi-task
approach, including both the properties of mutual information and spin correlations, is necessary to capture the difference between the topological SPT phase and the trivial SPT phase. The
emergence of clusters related to different phases of matter suggests that the state representation produced by our network also contains quantitative information about the topological
invariant \({{{\mathcal{Z}}}}_{{{\rm{R}}}}\). To extract this information, we use an additional neural network, which maps the state representation into a prediction of
\({{{\mathcal{Z}}}}_{{{\rm{R}}}}\). We train this additional network by randomly selecting 60 reference states (marked by gray squares in Fig. 7e) out of the set of 441 fiducial states, and
by minimizing the prediction error on the reference states. The predictions together with 60 exact values of the reference states are shown in Fig. 7e The absolute values of the differences
between the predictions and ground truths are shown in Fig. 7f. The predictions are close to the ground truths, except for the ground states near the phase boundaries, especially the
boundary of topological SPT phase. The mismatch at the phase boundaries corresponds the state representations incorrectly clustered in Fig. 7a, suggesting our network struggles to learn
long-range correlations at phase boundaries. GENERALIZATION TO QUANTUM SYSTEMS OF LARGER SIZE We now show that our model is capable of extracting features that are transferable across
different system sizes. To this purpose, we use a training dataset generated from 10-qubit ground states of the bond-alternating XXZ model (3) and then we use the trained network to generate
state representations from the local measurement data of each 50-qubit ground state of (3). Note that, since we use measurements on subsystems of fixed size, the size of the input to our
neural network remains constant during both training and testing, independently of the total number of qubits in the system. During training on 10-qubit systems, the network is informed by
the index of the first qubit in each qubit triplet, which ranges from 0 to 7. For testing, this index ranges from 0 to 47. This index primarily labels the triplets without carrying specific
meaning. Numerical experiments below show that this index does not significantly affect the quality of predictions, likely due to the approximate translational symmetry. Alternatively,
one-hot encoding could specify qubit triplets, but this would complicate the neural network and introduce size dependence. Figure 8a shows that inputting the state representations into the
t-SNE algorithm still gives rise to clusters according to the three distinct phases of matter. This observation suggests that the neural network can effectively classify different phases of
the bond-alternating XXZ model, irrespective of the system size. In addition to clustering larger quantum states, the representation network also facilitates the prediction of quantum
properties in the larger system. To demonstrate this capability, we employ 40 reference ground states of the 50-qubit bond-alternating XXZ model, which are only half size of the training
dataset used for 10-qubit system, to train two prediction networks: one for spin correlations and the other for mutual information. Figure 8b shows the coefficients of determination for each
prediction, which exhibit values around 0.9 or above. Figure 8b also shows the impact of inaccurate labeling of the ground states on our model. In the reported experiments, we assumed that
10% of the labels in the training dataset corresponding to 40 reference states are randomly incorrect, while the remaining 90% are accurate. Without any mitigation, we observe that the error
substantially impacts the accuracy of our predictions. On the other hand, employing a technique of noise mitigation during the training of prediction networks (see Supplementary Note 6) can
effectively reduce the impact of the incorrect labels. MEASURING ALL QUBITS SIMULTANEOUSLY We now apply our multi-task network to a scenario where all qubits are measured simultaneously
with suitable product observables. This scenario is motivated by recent experiments on trapped-ion systems33,36,37. In these experiments, the qubits were divided into groups of equal size,
and the same product of Pauli observables was measured simultaneously in all groups. Here, we adopt the settings of33,36, where the groups consist of three neighboring qubits. We consider
the ground states of a 50-qubits XXZ model and take \({{\mathcal{M}}}\) to be the the set of all 27 measurements that measure the same three-qubit Pauli observable on each triplet. Compared
to the set of 350 products of Pauli observables on all qubits, this choice significantly reduces the number of measurement settings the experimenter has to sample from. As an example, we
choose \({{\mathcal{S}}}\subset {{\mathcal{M}}}\) as the set of three measurements corresponding to the cyclically permuted Pauli strings \({\sigma }_{1}^{x}{\sigma }_{2}^{y}{\sigma
}_{3}^{z}{\sigma }_{4}^{x}{\sigma }_{5}^{y}{\sigma }_{6}^{z}\cdots {\sigma }_{50}^{y}\), \({\sigma }_{1}^{y}{\sigma }_{2}^{z}{\sigma }_{3}^{x}{\sigma }_{4}^{y}{\sigma }_{5}^{z}{\sigma
}_{6}^{x}\cdots {\sigma }_{50}^{z}\), and \({\sigma }_{1}^{z}{\sigma }_{2}^{x}{\sigma }_{3}^{y}{\sigma }_{4}^{z}{\sigma }_{5}^{x}{\sigma }_{6}^{y}\cdots {\sigma }_{50}^{x}\). For each copy
of the quantum state, we randomly sample a measurement from \({{\mathcal{S}}}\) to apply to the state and perform a total of 300 measurements. We then use the marginal distributions of the
outcomes on every qubit triplet as the input to our representation network to produce state representations. Figure 9a shows the 2D projections of our data-driven state representations of 49
ground states of the bond-alternating XXZ model obtained using the t-SNE algorithm, where all three different phases are clearly classified. It is interesting to compare the performance of
our neural network algorithm with the approach of principal component analysis (PCA) with shadow kernel26. In the original classical shadow method, measurements are randomly chosen from the
set of all possible Pauli measurements. To make a fair comparison, here we assume that the set of measurements performed in the laboratory is \({{\mathcal{S}}}\), the set of measurements
used by our method. Figure 9b shows the 2D projections of the shadow representations of the same set of ground states obtained by kernel PCA. The results show that PCA with the shadow kernel
can hardly distinguish the topological SPT phase from the trivial SPT phase in this restricted measurement setting. In contrast, our multi-task learning network appears to achieve a good
performance in distinguishing the different phases. DISCUSSION The use of short-range local measurements is a key distinction between our work and prior approaches approaches using
randomized measurements22,23,24,25,26,27. Rather than performing randomized measurements over all spins together, we employ only randomized Pauli measurements detecting short-range
correlations. This feature is appealing for practical applications, as measuring only short-range correlations can significantly reduce the number of measurement settings probed in the
laboratory. Under restrictions on the set of Pauli measurements sampled in the laboratory, our algorithm outperforms the previous methods using classical shadows. On the other hand, the
restriction to short-range local measurements implies that the applicability of our method is limited to many-body quantum states with a constant correlation length, such as ground states
within an SPT phase. A crucial aspect of our neural network model is its ability to generate a latent state representation that integrates different pieces of information, corresponding to
multiple physical properties. Remarkably, the state representations appear to capture information about properties beyond those encountered in training. This feature allows for unsupervised
classification of phases of matter, applicable not only to in-distribution Hamiltonian ground states but also to out-of-distribution quantum states, like those produced by random circuits.
The model also appears to be able to generalize from smaller to larger quantum systems, which makes it an effective tool for exploring intermediate-scale quantum systems. For new quantum
systems, whose true phase diagrams is still unknown, discovering phase diagrams in an unsupervised manner is a major challenge. This challenge can potentially be addressed by combining our
neural network with consistency-checking, similar to the approach in ref. 18. The idea is to start with an initial, potentially inaccurate, phase diagram ansatz constructed from limited
prior knowledge, for instance, the results of clustering. Then, one can randomly select a set of reference states, labeling them according to the ansatz phases. Based on these labels, a
separate neural network is trained to predict phases. Finally, the ansatz can be revised based on the deviation with the network’s prediction, and the procedure can be iterated until it
converges to a stable ansatz. In Supplementary Note 7, we provide examples of this approach, leaving the development of a full algorithm for autonomous discovery of phase diagram as future
work. METHODS DATA GENERATION Here we illustrate the procedures for generating training and test datasets. For the one-dimensional cluster-Ising model, we obtain measurement statistics and
values for various properties in both the training and test datasets through direct calculations, leveraging the ground states solved by exact algorithms. In the case of the one-dimensional
bond-alternating XXZ model, we first obtain approximate ground states represented by matrix product states48,49 using the density-matrix renormalization group (DMRG)50 algorithm.
Subsequently, we compute the measurement statistics and properties by contracting the tensor networks. For the noisy measurement statistics because of finite sampling, we generate them by
sampling from the actual probability distribution of measurement outcomes. More details are provided in Supplementary Note 1. REPRESENTATION NETWORK The representation network operates on
pairs of measurement outcome distributions and the parameterization of their corresponding measurements, denoted as \({({{{\bf{d}}}}_{i},\,{{{\bf{m}}}}_{i})}_{i=1}^{m}\) associated with a
state _ρ_. This network primarily consists of three multilayer perceptrons (MLPs)51. The first MLP comprises a four-layer architecture that transforms the measurement outcome distribution
into \({{{\bf{h}}}}_{i}^{d}\), whereas the second two-layer MLP maps the corresponding M_i_ to \({{{\bf{h}}}}_{i}^{m}\): $${{{\bf{h}}}}_{i}^{d}=\, {{{\rm{MLP}}}}_{1}({{{\bf{d}}}}_{i}),\\
{{{\bf{h}}}}_{i}^{m}=\, {{{\rm{MLP}}}}_{2}({{{\bf{m}}}}_{i}).$$ Next, we merge \({{{\bf{h}}}}_{i}^{d}\) and \({{{\bf{h}}}}_{i}^{m}\), feeding them into another three-layer MLP to obtain a
partial representation denoted as R_i_ for the state: $${{{\bf{r}}}}_{\rho }^{(i)}={{{\rm{MLP}}}}_{3}\left(\left[{{{\bf{h}}}}_{i}^{d},{{{\bf{h}}}}_{i}^{m}\right]\right).$$ (5) Following
this, we aggregate all the R_i_ representations through an average pooling layer to produce the complete state representation, denoted as R_ρ_: $${{{\bf{r}}}}_{\rho }=\frac{1}{s}{\sum
}_{i=1}^{s}{{{\bf{r}}}}_{i}.$$ (6) Alternatively, we can leverage a recurrent neural network equipped with gated recurrent units (GRUs)52 to derive the comprehensive state representation
from the set \({\{{{{\bf{r}}}}_{i}\}}_{i=1}^{m}\): $${{{\bf{z}}}}_{i}=\, {{\rm{sigmoid}}}\left({W}_{z}{{{\bf{r}}}}_{\rho }^{(i)}+{U}_{z}{{{\bf{r}}}}_{\rho
}^{(i-1)}+{{{\bf{b}}}}_{{{\bf{z}}}}\right),\\ {\hat{{{\bf{h}}}}}_{i}=\, \tanh \left({W}_{h}{{{\bf{r}}}}_{\rho }^{(i)}+{U}_{h}({{{\bf{z}}}}_{i}\odot
{{{\bf{h}}}}_{i-1})+{{{\bf{b}}}}_{{{\bf{h}}}}\right),\\ {{{\bf{h}}}}_{i}=\, (1-{{{\bf{z}}}}_{i})\odot {{{\bf{h}}}}_{i-1}+{{{\bf{z}}}}_{i}\odot {\hat{{{\bf{h}}}}}_{i},\\ {{{\bf{r}}}}_{\rho
}=\, {{{\bf{h}}}}_{m},$$ where _W_, _U_, B are trainable matrices and vectors. The architecture of the recurrent neural network offers a more flexible approach to generate the complete state
representation; however, in our experiments, we did not observe significant advantages compared to the average pooling layer. RELIABILITY OF REPRESENTATIONS The neural network can assess
the reliability of each state representation by conducting contrastive analysis within the representation space. Figure 10 shows a measure of the reliability of each state representation,
which falls in the region [0, 1], for both the cluster-Ising model and the bond-alternating XXZ model. As this measure increases from 0 to 1, the reliability of the corresponding prediction
strengthens, with values closer to 0 indicating low reliability and values closer to 1 indicating high reliability. Figure 10a indicates that the neural network exhibits lower confidence for
the ground states in SPT phase than those in the other two phases, with the lowest confidence occurring near the phase boundaries. Figure 10b shows that the reliability of predictions for
the ground states of the XXZ model in two SPT phases are higher than those in the symmetry broken phase, which is due to the imbalance of training data, and that the predictions for quantum
states near the phase boundaries have the lowest reliability. Here, the reliability is associated with the distance between the state representation and its cluster center in the
representation space. We adopt this definition based on the intuition that for a quantum state that the model should exhibit higher confidence for quantum states that cluster more easily.
Distance-based methods53,54 have proven effective in the task of Out-of-Distribution detection in classical machine learning. This task focuses on identifying instances that significantly
deviate from the data distribution observed during training, thereby potentially compromising the reliability of the trained neural network. Motivated by this line of research, we present a
contrastive methodology for assessing the reliability of representations produced by the proposed neural model. Denote the set of representations corresponding quantum states as
\(\{{{{\bf{r}}}}_{{\rho }_{1}},{{{\bf{r}}}}_{{\rho }_{2}},\cdots \,,{{{\bf{r}}}}_{{\rho }_{n}}\}\). We leverage reachability distances, \({\{{d}_{{\rho }_{j}}\}}_{j=1}^{n}\), derived from
the OPTICS (Ordering Points To Identify the Clustering Structure) clustering algorithm55 to evaluate the reliability of representations, denoted as \({\{r{v}_{{\rho }_{j}}\}}_{j=1}^{n}\):
$${\{{d}_{{\rho }_{j}}\}}_{j=1}^{n}=\, {{\rm{OPTICS}}}\left({\{\phi ({{{\bf{r}}}}_{{\rho }_{j}})\}}_{j=1}^{n}\right),\\ r{v}_{{\rho }_{j}}=\, \frac{\exp (-{d}_{{\rho }_{k}})} {{{\max
}_{k=1}^{n} \exp (-{d}_{{\rho }_{k}})}},$$ where _ϕ_ is a feature encoder. In the OPTICS clustering algorithm, a smaller reachability distance indicates that the associated point lies closer
to the center of its corresponding cluster, thereby facilitating its clustering process. Intuitively, a higher density within a specific region of the representation space indicates that
the trained neural model has had more opportunities to gather information from that area, thus enhancing its reliability. Our proposed method is supported by similar concepts introduced in
ref. 54. More details are provided in Supplementary Note 3. PREDICTION NETWORK For each type of property associated with the state, we employ a dedicated prediction network responsible for
making predictions. Each prediction network is composed of three MLPs. The first MLP takes the state representation R_ρ_ as input and transforms it into a feature vector HR while the second
takes the query task index _q_ as input and transforms it into a feature vector H_q_. The second MLP operates on the combined feature vectors [HR, H_q_] to produce the prediction _f__q_(_ρ_)
for the property under consideration: $${{{\bf{h}}}}^{{{\bf{r}}}}=\, {{{\rm{MLP}}}}_{4}({{{\bf{r}}}}_{\rho }),\\ {{{\bf{h}}}}^{q}=\, {{{\rm{MLP}}}}_{5}(q),\\ {f}_{q}(\rho )=\,
{{{\rm{MLP}}}}_{6}([{{{\bf{h}}}}^{{{\bf{r}}}},\,{{{\bf{h}}}}^{q}]).$$ NETWORK TRAINING We employ the stochastic gradient descent56 optimization algorithm and the Adam optimizer57 to train
our neural network. In our training procedure, for each state within the training dataset, we jointly train both the representation network and the prediction networks associated with one or
two types of properties available for that specific state. The training loss is the cumulative sum of losses across different states and properties. This training is achieved by minimizing
the difference between the predicted values generated by the network and the ground-truth values, thus refining the model’s ability to capture and reproduce the desired property
characteristics. The detailed pseudocode for the training process can be found in Supplementary Note 2. NETWORK TEST & TRANSFER LEARNING After the training is concluded, the multi-task
networks are fixed. To evaluate the performance of the trained model, we perform a series of tests on a separate dataset that includes states not seen during training. This evaluation helps
in assessing the model’s ability to generalize to new data. To achieve transfer learning for new tasks using state representations produced by the representation network, we first fix the
representation network and obtain the state representations. We then introduce a new prediction network that takes these state representations as input, allowing us to leverage the
pre-trained representations to predict new properties. During the training of this new task, we use the Adam optimizer57 and stochastic gradient descent56 to minimize the prediction error.
Once the training is complete, we fix this new prediction network and test its performance on previously unseen states to evaluate its generalization capability. HARDWARE We employ the
PyTorch framework58 to construct the multi-task neural networks in all our experiments and train them with two NVIDIA GeForce GTX 1080 Ti GPUs. DATA AVAILABILITY Data sets generated during
the current study are available in https://github.com/yzhuqici/learn_quantum_properties_from_local_correlation. CODE AVAILABILITY The codes that support the findings of this study are
available in https://github.com/yzhuqici/learn_quantum_properties_from_local_correlation. REFERENCES * Torlai, G. et al. Neural-network quantum state tomography. _Nat. Phys._ 14, 447–450
(2018). Article CAS Google Scholar * Carrasquilla, J., Torlai, G., Melko, R. G. & Aolita, L. Reconstructing quantum states with generative models. _Nat. Mach. Intell._ 1, 155–161
(2019). Article Google Scholar * Zhu, Y. et al. Flexible learning of quantum states with generative query neural networks. _Nat. Commun._ 13, 6222 (2022). Article ADS PubMed PubMed
Central CAS Google Scholar * Schmale, T., Reh, M. & Gärttner, M. Efficient quantum state tomography with convolutional neural networks. _NPJ Quantum Inf._ 8, 115 (2022). Article ADS
Google Scholar * Carleo, G. & Troyer, M. Solving the quantum many-body problem with artificial neural networks. _Science_ 355, 602–606 (2017). Article ADS MathSciNet PubMed CAS
Google Scholar * Zhang, X. et al. Direct fidelity estimation of quantum states using machine learning. _Phys. Rev. Lett._ 127, 130503 (2021). Article ADS PubMed CAS Google Scholar *
Xiao, T., Huang, J., Li, H., Fan, J. & Zeng, G. Intelligent certification for quantum simulators via machine learning. _NPJ Quantum Inf._ 8, 138 (2022). Article ADS CAS Google Scholar
* Du, Y. et al. Shadownet for data-centric quantum system learning. _arXiv preprint arXiv:2308.11290_ (2023). * Wu, Y.-D., Zhu, Y., Bai, G., Wang, Y. & Chiribella, G. Quantum
similarity testing with convolutional neural networks. _Phys. Rev. Lett._ 130, 210601 (2023). Article ADS PubMed CAS Google Scholar * Qian, Y., Du, Y., He, Z., Hsieh, M.-H. & Tao,
D. Multimodal deep representation learning for quantum cross-platform verification. _Phys. Rev. Lett._ 133, 130601 (2024). * Gao, J. et al. Experimental machine learning of quantum states.
_Phys. Rev. Lett._ 120, 240501 (2018). Article ADS PubMed CAS Google Scholar * Gray, J., Banchi, L., Bayat, A. & Bose, S. Machine-learning-assisted many-body entanglement
measurement. _Phys. Rev. Lett._ 121, 150503 (2018). Article ADS PubMed CAS Google Scholar * Koutnỳ, D. et al. Deep learning of quantum entanglement from incomplete measurements. _Sci.
Adv._ 9, eadd7131 (2023). Article PubMed PubMed Central Google Scholar * Torlai, G. et al. Integrating neural networks with a quantum simulator for state reconstruction. _Phys. Rev.
Lett._ 123, 230504 (2019). Article ADS PubMed CAS Google Scholar * Huang, Y. et al. Measuring quantum entanglement from local information by machine learning. _arXiv preprint
arXiv:2209.08501_ (2022). * Smith, A. W. R., Gray, J. & Kim, M. S. Efficient quantum state sample tomography with basis-dependent neural networks. _PRX Quantum_ 2, 020348 (2021). Article
ADS Google Scholar * Carrasquilla, J. & Melko, R. G. Machine learning phases of matter. _Nat. Phys._ 13, 431–434 (2017). Article CAS Google Scholar * Van Nieuwenburg, E. P., Liu,
Y.-H. & Huber, S. D. Learning phase transitions by confusion. _Nat. Phys._ 13, 435–439 (2017). Article Google Scholar * Huembeli, P., Dauphin, A. & Wittek, P. Identifying quantum
phase transitions with adversarial neural networks. _Phys. Rev. B_ 97, 134109 (2018). Article ADS CAS Google Scholar * Rem, B. S. et al. Identifying quantum phase transitions using
artificial neural networks on experimental data. _Nat. Phys._ 15, 917–920 (2019). Article CAS Google Scholar * Kottmann, K., Huembeli, P., Lewenstein, M. & Acín, A. Unsupervised phase
discovery with deep anomaly detection. _Phys. Rev. Lett._ 125, 170603 (2020). Article ADS MathSciNet PubMed CAS Google Scholar * Huang, H.-Y., Kueng, R. & Preskill, J. Predicting
many properties of a quantum system from very few measurements. _Nat. Phys._ 16, 1050–1057 (2020). Article CAS Google Scholar * Elben, A. et al. Cross-platform verification of
intermediate scale quantum devices. _Phys. Rev. Lett._ 124, 010504 (2020). Article ADS PubMed CAS Google Scholar * Elben, A. et al. Many-body topological invariants from randomized
measurements in synthetic quantum matter. _Sci. Adv._ 6, eaaz3666 (2020). Article ADS PubMed PubMed Central Google Scholar * Huang, H.-Y. Learning quantum states from their classical
shadows. _Nat. Rev. Phys._ 4, 81–81 (2022). Article Google Scholar * Huang, H.-Y., Kueng, R., Torlai, G., Albert, V. V. & Preskill, J. Provably efficient machine learning for quantum
many-body problems. _Science_ 377, eabk3333 (2022). Article MathSciNet PubMed CAS Google Scholar * Elben, A. et al. The randomized measurement toolbox. _Nat. Rev. Phys._ 5, 9–24 (2023).
Article Google Scholar * Zhao, H. et al. Learning quantum states and unitaries of bounded gate complexity. _arXiv preprint arXiv:2310.19882_ (2023). * Hu, H.-Y., Choi, S. & You, Y.-Z.
Classical shadow tomography with locally scrambled quantum dynamics. _Phys. Rev. Res._ 5, 023027 (2023). Article CAS Google Scholar * Hu, H.-Y. et al. Demonstration of robust and
efficient quantum property learning with shallow shadows. _arXiv preprint arXiv:2402.17911_ (2024). * Cramer, M. et al. Efficient quantum state tomography. _Nat. Commun._ 1, 149 (2010).
Article ADS PubMed Google Scholar * Baumgratz, T., Nüßeler, A., Cramer, M. & Plenio, M. B. A scalable maximum likelihood method for quantum state tomography. _N. J. Phys._ 15, 125004
(2013). Article Google Scholar * Lanyon, B. et al. Efficient tomography of a quantum many-body system. _Nat. Phys._ 13, 1158–1162 (2017). Article CAS Google Scholar * Kurmapu, M. K. et
al. Reconstructing complex states of a 20-qubit quantum simulator. _PRX Quantum_ 4, 040345 (2023). Article ADS Google Scholar * Guo, Y. & Yang, S. Quantum state tomography with
locally purified density operators and local measurements. _Commun. Phys._ 7, 322 (2024). * Friis, N. et al. Observation of entangled states of a fully controlled 20-qubit system. _Phys.
Rev. X_ 8, 021012 (2018). CAS Google Scholar * Joshi, M. K. et al. Exploring large-scale entanglement in quantum simulation. _Nature_ 624, 539–544 (2023). Article ADS PubMed CAS Google
Scholar * Zhang, Y. & Yang, Q. A survey on multi-task learning. _IEEE Trans. Knowl. Data Eng._ 34, 5586–5609 (2021). Article Google Scholar * Klyachko, A. A. et al. Quantum marginal
problem and n-representability. _J. Physi.: Conf. Series_, 36, 72 (IOP Publishing, 2006). * Christandl, M. & Mitchison, G. The spectra of quantum states and the kronecker coefficients of
the symmetric group. _Commun. Math. Phys._ 261, 789–797 (2006). Article ADS MathSciNet Google Scholar * Schilling, C. et al. _The Quantum Marginal Problem._ In _Mathematical Results in
Quantum Mechanics: Proceedings of the QMath12 Conference_, 165–176 (World Scientific, 2015). * Pollmann, F. & Turner, A. M. Detection of symmetry-protected topological phases in one
dimension. _Phys. Rev. B_ 86, 125441 (2012). Article ADS Google Scholar * Smacchia, P. et al. Statistical mechanics of the cluster Ising model. _Phys. Rev. A_ 84, 022304 (2011). Article
ADS Google Scholar * Cong, I., Choi, S. & Lukin, M. D. Quantum convolutional neural networks. _Nat. Phys._ 15, 1273–1278 (2019). Article CAS Google Scholar * Herrmann, J. et al.
Realizing quantum convolutional neural networks on a superconducting quantum processor to recognize quantum phases. _Nat. Commun._ 13, 4144 (2022). Article ADS PubMed PubMed Central
Google Scholar * Cohen, P. R. & Howe, A. E. How evaluation guides ai research: the message still counts more than the medium. _AI Mag._ 9, 35–35 (1988). Google Scholar * Liu, Y.-J.,
Smith, A., Knap, M. & Pollmann, F. Model-independent learning of quantum phases of matter with quantum convolutional neural networks. _Phys. Rev. Lett._ 130, 220603 (2023). Article ADS
MathSciNet PubMed CAS Google Scholar * Fannes, M., Nachtergaele, B. & Werner, R. F. Finitely correlated states on quantum spin chains. _Commun. Math. Phys._ 144, 443–490 (1992).
Article ADS MathSciNet Google Scholar * Perez-García, D., Verstraete, F., Wolf, M. M. & Cirac, J. I. Matrix product state representations. _Quantum Inf. Comput._ 7, 401–430 (2007).
MathSciNet Google Scholar * Schollwöck, U. The density-matrix renormalization group. _Rev. Mod. Phys._ 77, 259 (2005). Article ADS MathSciNet Google Scholar * Gardner, M. W. &
Dorling, S. Artificial neural networks (the multilayer perceptron)—a review of applications in the atmospheric sciences. _Atmos. Environ._ 32, 2627–2636 (1998). Article ADS CAS Google
Scholar * Chung, J., Gulcehre, C., Cho, K. & Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. In _NIPS 2014 Workshop on Deep Learning, December
2014_ (2014). * Lee, K., Lee, K., Lee, H. & Shin, J. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. _Advances in neural information
processing systems_ 31, (2018). * Sun, Y., Ming, Y., Zhu, X. & Li, Y. Out-of-distribution detection with deep nearest neighbors. In _International Conference on Machine Learning_,
20827–20840 (PMLR, 2022). * Ankerst, M., Breunig, M. M., Kriegel, H.-P. & Sander, J. Optics: Ordering points to identify the clustering structure. _ACM Sigmod Rec._ 28, 49–60 (1999).
Article Google Scholar * Bottou, L. et al. Stochastic gradient descent tricks. In _Neural Networks: Tricks of the Trade: Second Edition_, 421–436 (Springer, 2012). * Kingma, D. P. &
Ba, J. Adam: A method for stochastic optimization. _arXiv preprint arXiv:1412.6980_ (2014). * Paszke, A. et al. Pytorch: An imperative style, high-performance deep learning library.
_Advances in neural information processing systems_32 (2019). * Williamson, D. F., Parker, R. A. & Kendrick, J. S. The box plot: a simple visual method to interpret data. _Ann. Intern.
Med._ 110, 916–921 (1989). Article PubMed CAS Google Scholar Download references ACKNOWLEDGEMENTS We thank Ge Bai, Dong-Sheng Wang, Shuo Yang, Yuchen Guo and Jiehang Zhang for the
helpful discussions on many-body quantum systems. This work was supported by funding from the Hong Kong Research Grant Council through grants no. 17300918 and no. 17307520 (GC), through the
Senior Research Fellowship Scheme SRFS2021-7S02 (GC), the Chinese Ministry of Science and Education through grant 2023ZD0300600 (GC), and the John Templeton Foundation through grant 62312
(GC), The Quantum Information Structure of Spacetime (qiss.fr). YDW acknowledges funding from the National Natural Science Foundation of China through grants no. 12405022. YXW acknowledges
funding from the National Natural Science Foundation of China through grants no. 61872318. Research at the Perimeter Institute is supported by the Government of Canada through the Department
of Innovation, Science and Economic Development Canada and by the Province of Ontario through the Ministry of Research, Innovation and Science. The opinions expressed in this publication
are those of the authors and do not necessarily reflect the views of the John Templeton Foundation. AUTHOR INFORMATION Author notes * These authors contributed equally: Ya-Dong Wu, Yan Zhu.
AUTHORS AND AFFILIATIONS * John Hopcroft Center for Computer Science, Shanghai Jiao Tong University, Shanghai, China Ya-Dong Wu * QICI Quantum Information and Computation Initiative,
Department of Computer Science, The University of Hong Kong, Pokfulam Road, Hong Kong, Hong Kong Ya-Dong Wu, Yan Zhu & Giulio Chiribella * AI Technology Lab, Department of Computer
Science, The University of Hong Kong, Pokfulam Road, Hong Kong, Hong Kong Yuexuan Wang * College of Computer Science and Technology, Zhejiang University, Hangzhou, Zhejiang Province, China
Yuexuan Wang * Department of Computer Science, Parks Road, Oxford, United Kingdom Giulio Chiribella * Perimeter Institute for Theoretical Physics, Waterloo, Ontario, Canada Giulio Chiribella
Authors * Ya-Dong Wu View author publications You can also search for this author inPubMed Google Scholar * Yan Zhu View author publications You can also search for this author inPubMed
Google Scholar * Yuexuan Wang View author publications You can also search for this author inPubMed Google Scholar * Giulio Chiribella View author publications You can also search for this
author inPubMed Google Scholar CONTRIBUTIONS Y.-D.W. and Y.Z. developed the key idea for this paper. Y.Z. conducted the numerical experiments while G.C. and Y.W. contributed to their design.
All coauthors contributed to the writing of the manuscript. CORRESPONDING AUTHORS Correspondence to Yan Zhu or Giulio Chiribella. ETHICS DECLARATIONS COMPETING INTERESTS The authors declare
no competing interests. PEER REVIEW PEER REVIEW INFORMATION _Nature Communications_ thanks Alistair Smith, and the other, anonymous, reviewers for their contribution to the peer review of
this work. A peer review file is available. ADDITIONAL INFORMATION PUBLISHER’S NOTE Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional
affiliations. SUPPLEMENTARY INFORMATION SUPPLEMENTARY INFORMATION PEER REVIEW FILE RIGHTS AND PERMISSIONS OPEN ACCESS This article is licensed under a Creative Commons
Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give
appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission
under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons
licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by
statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit
http://creativecommons.org/licenses/by-nc-nd/4.0/. Reprints and permissions ABOUT THIS ARTICLE CITE THIS ARTICLE Wu, YD., Zhu, Y., Wang, Y. _et al._ Learning quantum properties from
short-range correlations using multi-task networks. _Nat Commun_ 15, 8796 (2024). https://doi.org/10.1038/s41467-024-53101-y Download citation * Received: 07 November 2023 * Accepted: 30
September 2024 * Published: 11 October 2024 * DOI: https://doi.org/10.1038/s41467-024-53101-y SHARE THIS ARTICLE Anyone you share the following link with will be able to read this content:
Get shareable link Sorry, a shareable link is not currently available for this article. Copy to clipboard Provided by the Springer Nature SharedIt content-sharing initiative